- @weixin_42163563
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在AI与深度学习逐渐发展成熟的趋势下,人工智能和大数据等技术开始进入了医疗领域,它们把现有的一些传统流程进行优化,大幅度提高各种流程的效率、精度、用户体验,同时也缓解了医疗资源的压力和精确度不够的问题。智能医疗有很多的发展方向,例如医学影像处理、诊断预测、疾病控制、健康管理、康复机器人、语音识别病历电子化等。当前人工智能技术新的发力点中的医学图像在疾病的预测和自动化诊断方面有非常大的意义,本篇主要
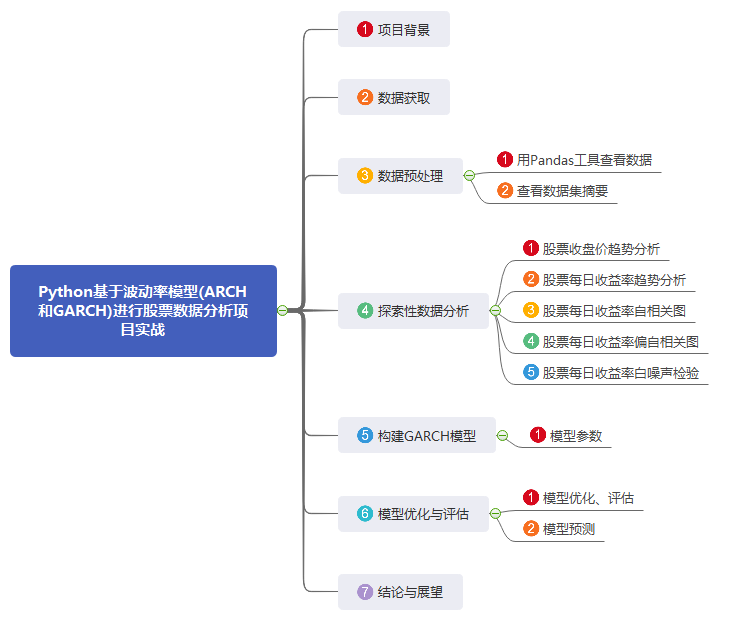
Python基于波动率模型(ARCH和GARCH)进行股票数据分析项目实战
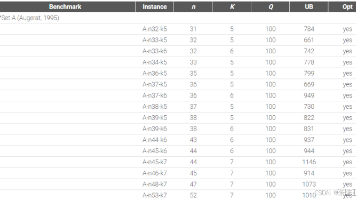
CVRPLIB是运筹学领域经典的容量约束车辆路径问题(CVRP)标准数据集库,包含Augerat、Christofides等学者提出的16组基准实例,涵盖从16到1000个客户的不同规模问题。数据集按提出时间分类,包含1969年的经典小规模测试集(如SetE)、1990年代中等规模集合(如SetM)、2000年后的大规模实例(如Li et al.)以及2014年Uchoa提出的高难度X系列。该库支
机器学习项目实战合集列表
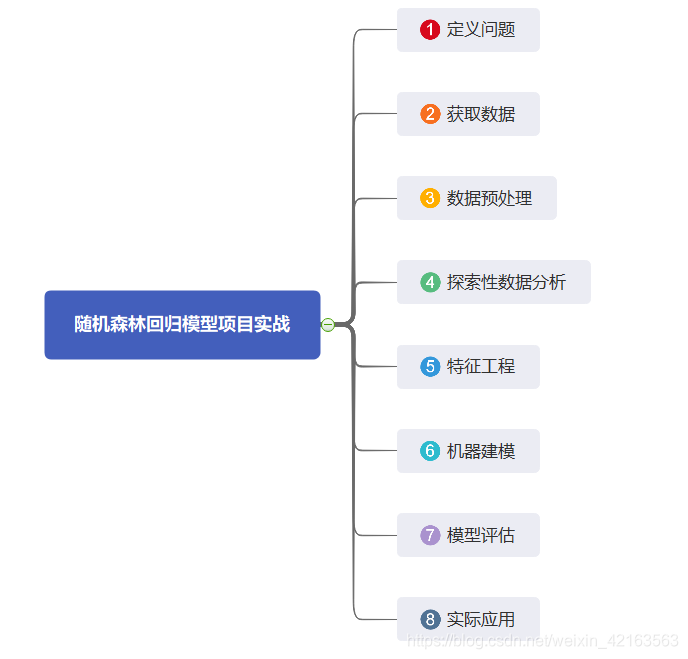
说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。1.定义问题在电子商务领域,现在越来越多的基于历史采购数据、订单数据等,进行销量的预测;本模型也是基于电商的一些历史数据进行销量的建模、预测。2.获取数据本数据是模拟数据,分为两部分数据:训练数据集:data_train.xlsx测试数据集:data_test.xlsx在实际应用中,根据自己的数据进行替换即
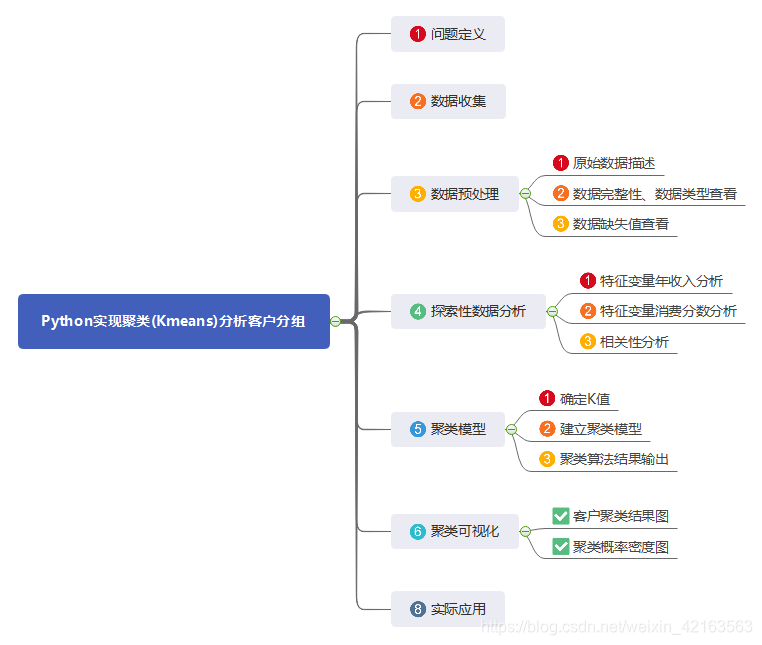
说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。1.问题定义在日常银行、电商等公司中,随着时间的推移,都会积累一些客户的数据。在当前的大数据时代、人工智能时代,数据就是无比的财富。并且消费者需求显现出日益差异化和个性化的趋势。随着我国市场化程度的逐步深入,以及信息技术的不断渗透,对大数据的分析已是必然趋势。本案例就是使用机器学习聚类算法对客户进行分组,为
前言:现在网络上有很多文章,数据和代码都不全,胖哥对此重新梳理后,把用到的数据和代码全部奉上,如果想直接要数据和代码,请查看文章最后,胖哥对此代码加了详细的注释!!!一、贝叶斯分类介绍贝叶斯分类器是一个统计分类器。它们能够预测类别所属的概率,如:一个数据对象属于某个类别的概率。贝叶斯分类器是基于贝叶斯定理而构造出来的。对分类方法进行比较的有关研究结果表明:简单贝叶斯分类器(称为基本贝叶斯分类器)在
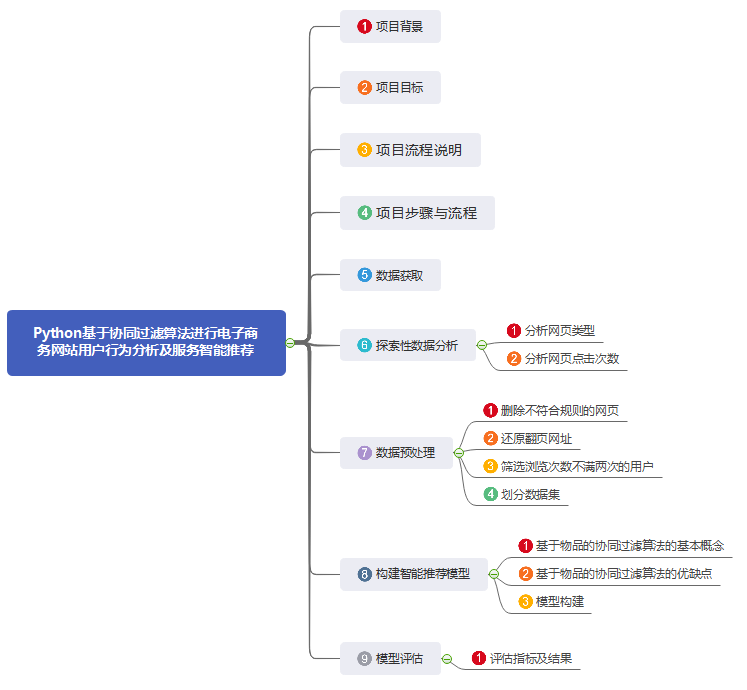
Python基于协同过滤算法进行电子商务网站用户行为分析及服务智能推荐
Python基于PyQt5和卷积神经网络分类模型(ResNet50分类算法)实现生活垃圾分类系统GUI界面项目实战

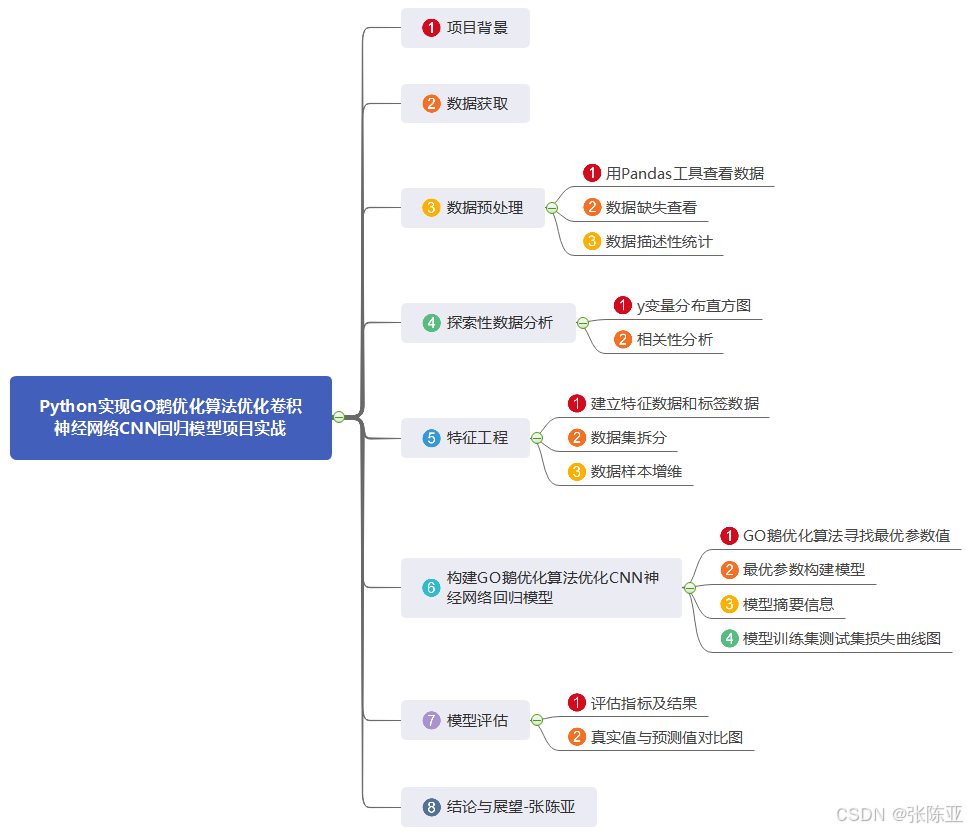
Python实现GO鹅优化算法优化卷积神经网络CNN回归模型项目实战