




- @weixin_40338859
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
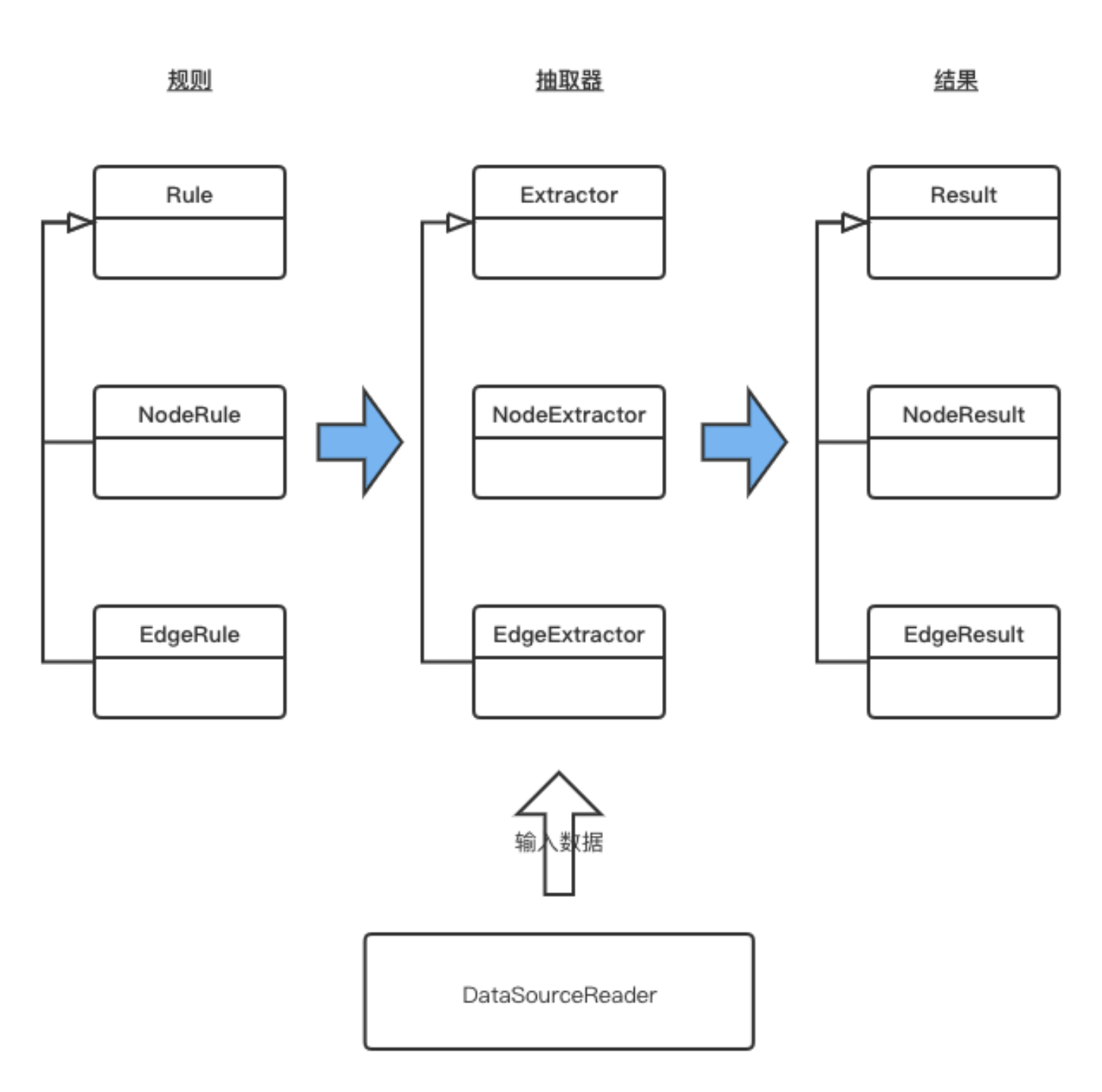
为了方便阅读,本文分成三篇文章进行发布,本文介绍抽取程序设计根据前文设计的抽取规则,基于面向对象思想,采用Java语言设计开发,实现了较好的程序结构设计。主体程序设计UML设计如下:设计说明:RowData作为核心数据结构,表示表中的一行数据,其他类都需要与RowData交互。为了便于实际数据格式扩展,RowData设计为接口,其方法getValue用于根据字段名获取字段值,并提供两个实现:Row
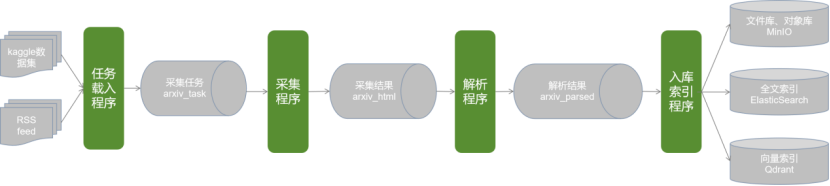
上一篇 文章介绍了arXiv采集处理的任务背景、整体需求,并对数据进行了调研。本文介绍整体方案设计。基于上述调研了解的情况,针对工作需求设计处理流程如下:由于流程较为复杂,如果采用普通的串行流程,虽然可以实现业务功能,但存在性能不佳、更新数据不及时、添加采集任务不灵活等问题。(思考:为什么会有这些问题?)很容易想到的解决办法是将流程拆分,分为论文采集流程、论文解析流程和建索引流程,通过不同的并行调
为了方便阅读,本文分成三篇文章进行发布,本文介绍抽取程序设计根据前文设计的抽取规则,基于面向对象思想,采用Java语言设计开发,实现了较好的程序结构设计。主体程序设计UML设计如下:设计说明:RowData作为核心数据结构,表示表中的一行数据,其他类都需要与RowData交互。为了便于实际数据格式扩展,RowData设计为接口,其方法getValue用于根据字段名获取字段值,并提供两个实现:Row
本文是基于规则的结构化数据知识抽取专题的第三篇,介绍知识抽取的交互设计知识图谱概念本身很容易理解,但是其建模设计、知识抽取、知识融合等过程较为复杂,如果能够通过WYSWYG(所见即所得)的方式指引用户,将为应用带来极大便利。与本文内容最相关的是规则配置界面,通过设计交互界面,方便用户进行规则配置,此功能又称为本体映射。传统的信息化系统界面往往采用表单方式,配置过程枯燥繁琐,不易发现错误。1.界面要

上一篇 文章介绍了arXiv采集处理的任务背景、整体需求,并对数据进行了调研。本文介绍整体方案设计。基于上述调研了解的情况,针对工作需求设计处理流程如下:由于流程较为复杂,如果采用普通的串行流程,虽然可以实现业务功能,但存在性能不佳、更新数据不及时、添加采集任务不灵活等问题。(思考:为什么会有这些问题?)很容易想到的解决办法是将流程拆分,分为论文采集流程、论文解析流程和建索引流程,通过不同的并行调
为了方便阅读,本文分成三篇文章进行发布,本文先介绍技术背景、统一数据格式设计和规则设计;第二篇介绍抽取程序设计;第三篇介绍规则配置交互设计1. 背景知识抽取是从数据中提炼、萃取知识信息的过程。按照数据的结构化程度,分为结构化数据知识抽取、半结构化数据知识抽取和非结构化数据知识抽取。最常见的结构化数据是表格式数据,在传统的信息化系统中存在的大量关系数据库库表数据都是表格式数据,尽管其中一些字段可能是

最近对SmartETL(https://github.com/ictchenbo/SmartETL/)持续改进,在想对数据处理能不能提一个新的术语名词?我需要一个简单的概念,能够表示数据处理,包括加载、转换、过滤、清洗、计算、分析等等。:帮我构造一个简单的英文单词,表示数据处理的基本操作嗯,用户让我帮忙构造一个简单的英文单词,用来表示数据处理的基本操作。首先,我需要理解用户的需求。他们可能是在开发