




- @weixin_32393347
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这个初始设置很重要——我们在这里做出的每个选择,从我们安装的库到我们获取的数据,都将决定最终训练智能体的可靠性和可重现性。通过这种方式,我们积极寻找并整合来自多个来源的信息到智能体系统中,将它们从简单的推理器转变为积极的研究人员。通过创建一个可重用的**“工厂”**,我们确保系统中的每个智能体都以一致的方式构建,采用定义其角色的特定。这种方法为智能体的整个认知过程提供了机器可读的蓝图。,我们为智能
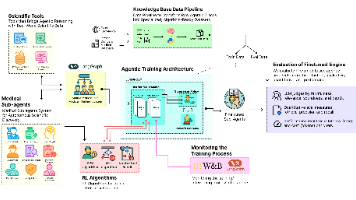
当前,安全运营领域正经历一场根本性变革,对智能自动化的需求达到了前所未有的高度。网络威胁攻击者每天都在利用人工智能发起攻击。今天,我想分享一种——如何借助 Splunk 模型上下文协议(MCP)服务器,结合 LangChain 与 LangGraph 框架,构建一个能够自主开展安全威胁调查的安全运营中心(SOC)分析智能体。
例如,如果你的完整需求说明书有一个关于“安全要求”的部分,长达500字,你可以让智能体将其总结为:“安全:使用HTTPS,保护API密钥,实现输入验证(参见完整需求说明书§4.2)”。许多使用多智能体设置的开发者甚至为每个部分创建单独的智能体或子进程——例如,一个智能体处理数据库/模式,另一个处理API逻辑,另一个处理前端——每个都有相关的需求说明书片段。如果你的公司标准化了某些技术,就在这里说明
用个现实例子说明白:同样是让订东京机票,大模型聊天机器人只会说:“这里有一些订票小贴士…”查你日历看有没有空搜索航班比价订最优选项加到你日历发确认信息给你AI代理会自主行动完成目标。LangGraph代理需要以特定方式定义工具。count: int@tool"""使用Subfinder(在Docker中运行)枚举子域名。使用证书透明度、DNS数据集和网络档案。"""文档字符串很重要,大模型决定是否

两个月。这就是 Boris Cherny——Anthropic 的 Claude Code 创造者兼负责人——在完全没有亲手写过一行代码的情况下度过的时间。这不是笔误,也不是夸张。“我甚至连小改动都不会手动去写。”Cherny 在 2026 年 1 月下旬发帖表示,“我昨天发了 22 个 PR,前一天发了 27 个,而且每一个都是 100% 由 Claude 编写的。看起来,这条蛇终于开始吞下自己
如果说 OpenClaw 让更多人看到了 AI 在个人生产力场景中的潜力,那么过去几个月的变化已经清楚说明了一件事:这些能力不再只停留在消费级工具层面。无论是围绕 OpenClaw 形成的区域性生态,还是厂商迅速将它包装为成套产品,一旦热门 AI 工具进入更复杂的应用环境,它们几乎总会进一步走向企业和行业场景。而企业真正需要的,不只是一个会聊天、会调用工具的智能体。他们需要的是一种系统环境:它能连
CLAUDE.md让你教会它规则。MEMORY.md让它保留合作经验。前者让它更听话,后者让它更连续。对于经常用 Claude Code 写代码的人来说,这不是小修小补。这是它第一次认真补上“第二天还认不认识你”这个最大短板。
如果你经常觉得自己学得慢,不一定是能力问题。很多时候,只是你的学习流程太重了。资料太多,入口太乱,准备成本太高,最后真正留给理解和复习的时间反而不多。NotebookLM的价值,不在于它比别的 AI 更会聊天。而在于它让学习这件事,终于围绕你的资料、你的重点和你的节奏展开。更聚焦,也更省力。如果你手上正好有一堆想读但一直没时间读完的材料,不妨拿一组主题试一次。你可能会第一次感觉到:原来高效学习,不
2026年AI Agent必备命令行工具摘要 随着AI Agent技术的发展,命令行工具(CLI)因其高效、低token消耗的特点重新成为开发者和AI助手的主流选择。本文推荐了2026年最值得关注的10个CLI工具: GitHub CLI(gh):终端内完成PR、Issue等GitHub操作 Stripe CLI:本地测试支付流程和webhook Supabase CLI:本地开发完整后端服务栈
Claude 返回没有工具调用的文本响应。任务完成。