- @weilexiao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
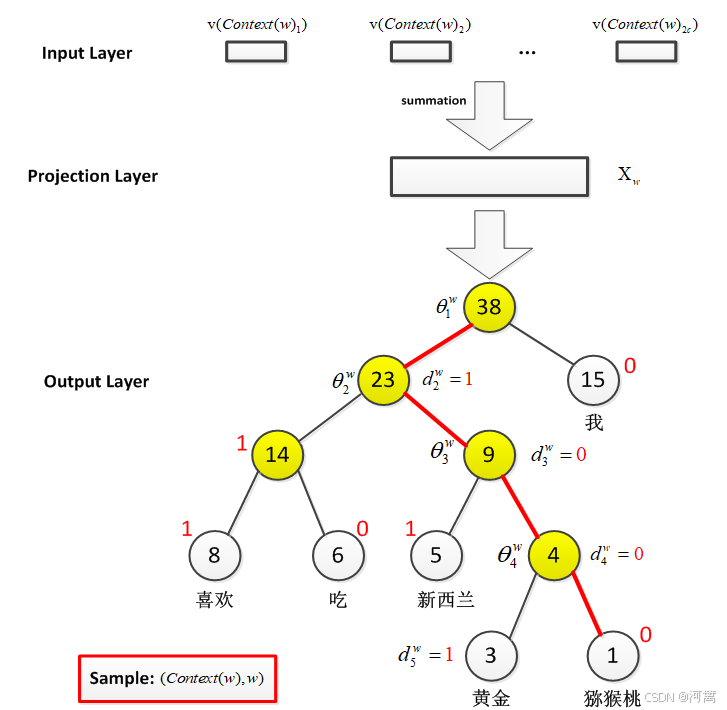
随机地给一个参数值得到一个语法,根据文法和训练语料,得到语法规则使用次数的期望值,以期望次数用最大似然估计得到语法参数新的估计值,得到新的语法,由得到的新语法得到使用次数期望值,重新估计语法参数。输入的句子可能是比较随性的,构造的分析树就容易出错,规则不一定覆盖所有的语言现象,有些应用不需要一个完全句法分析树,只需要告诉哪些词可以作为一个组块。方法:采用动态规划算法,将句法分析树的概率计算转化为句

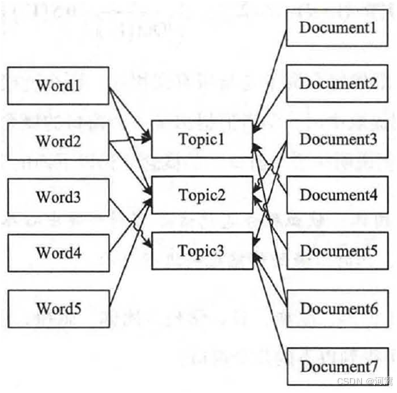
关键词:代表文章重要内容的一组词应用:信息获取、自动摘要、文本聚类、文本分类有监督学习无监督学习TF-IDFTextRank主题模型:LSA、LAI、LDA。
自然语言处理:词法分析
自然语言处理:统计语言模型
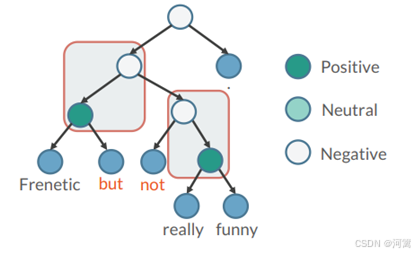
通过预训练语言模型得到情感语义树:将原始数据传进BERT中得到每一时刻的编码,将编码输入到attention中,包含1.计算上层的节点情感语义值时关注下层哪一部分,2.上层层与层之间的attention,输出为一颗情感语义树。输入基本序列经过编码后经过中间层对整句话进行情感分类,并找到其中的情感词,将除了情感词的其他部分都保留,对整句话进行重构,1.让情感化模块在有监督的情况下学习增加情感;思路:
自然语言处理:语言学基础
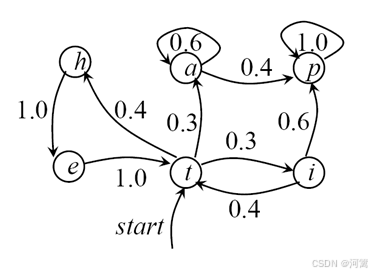
本文概况性讲述了马尔可夫模型、隐马尔可夫模型、词性标注相关概念
自然语言处理:NLP概述
第三范式:预训练+微调模式(详见自然语言处理9);预训练时海量数据不需要标注,即无监督学习;由于数据量很大使得参数量也可以很大。
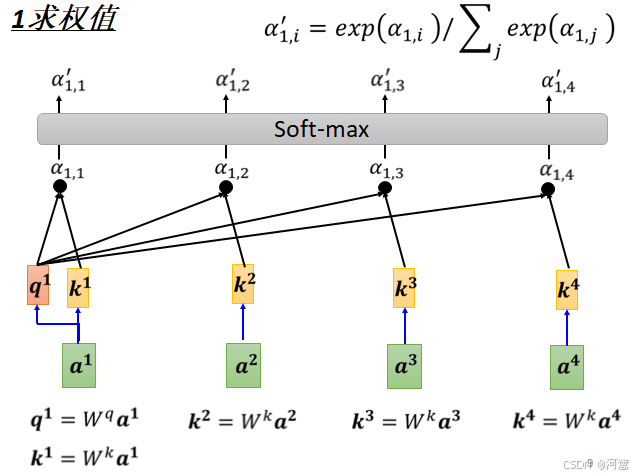
空出来的地方是需要模型训练的,即输出的是对空出来的地方的分类。传统:以普通文本或图数据库存储语料,来一个问句后对问句的类型进行分类,根据对问句的解析,到数据库中搜索,将得到的多个文本抽取出中心思想得出答案,再和问句比较一下是否有偏,修正后发出去。传统:抽取式,单文档按照句子的顺序抽出来句子,按段首的句子权重较高,有较多关键词的句子权重较高,有转折的句子后边权重更大点等给句子以权重;模型优化:CBO