- @w_t_f
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DreamVLA提出了一种新型视觉-语言-动作(VLA)模型,通过预测综合世界知识(动态、空间和语义信息)而非完整图像帧来改进机器人操作任务。该模型采用动态区域引导的世界知识预测和块状结构化注意力机制,避免不同模态间的信息干扰,并利用扩散Transformer解耦动作表示。实验显示,DreamVLA在真实机器人任务中达到76.7%的成功率,在CALVIN基准上优于现有方法。其紧凑的表示方式减少了冗
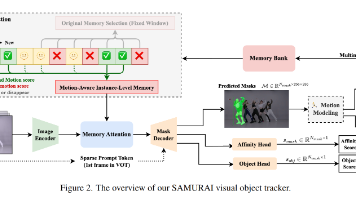
然而SAM2在预测后续帧的mask时,经常忽略运动信息,导致目标在快速移动或交互复杂的情况下不准确,在目标拥挤的场景中这种现象尤为明显,而SAM2倾向于优先考虑目标的外观相似性,而不是空间和时间的一致性,最终导致了跟踪错误。为了解决这一问题,我们提出将运动信息融合到SAM2的预测过程中,通过利用物体的历史运动轨迹,增强模型对于遮挡的相似物体间的跟踪能力。并不是非常稳健的指标,尤其是在存在相似目标相
本篇论文不是寻求注意力机制的新的创新,而是平衡点云处理中准确性和效率的trade-offs。借鉴3D large-scale表示学习,作者认识到模型性能更受规模scale的影响,而不是复杂设计。因此作者提出Point Transformer V3 (PTv3),优先考虑简单性和效率。例如,将KNN替换成序列化的邻域映射*。这一准则支持大规模scaling,将感受野receptive field从1
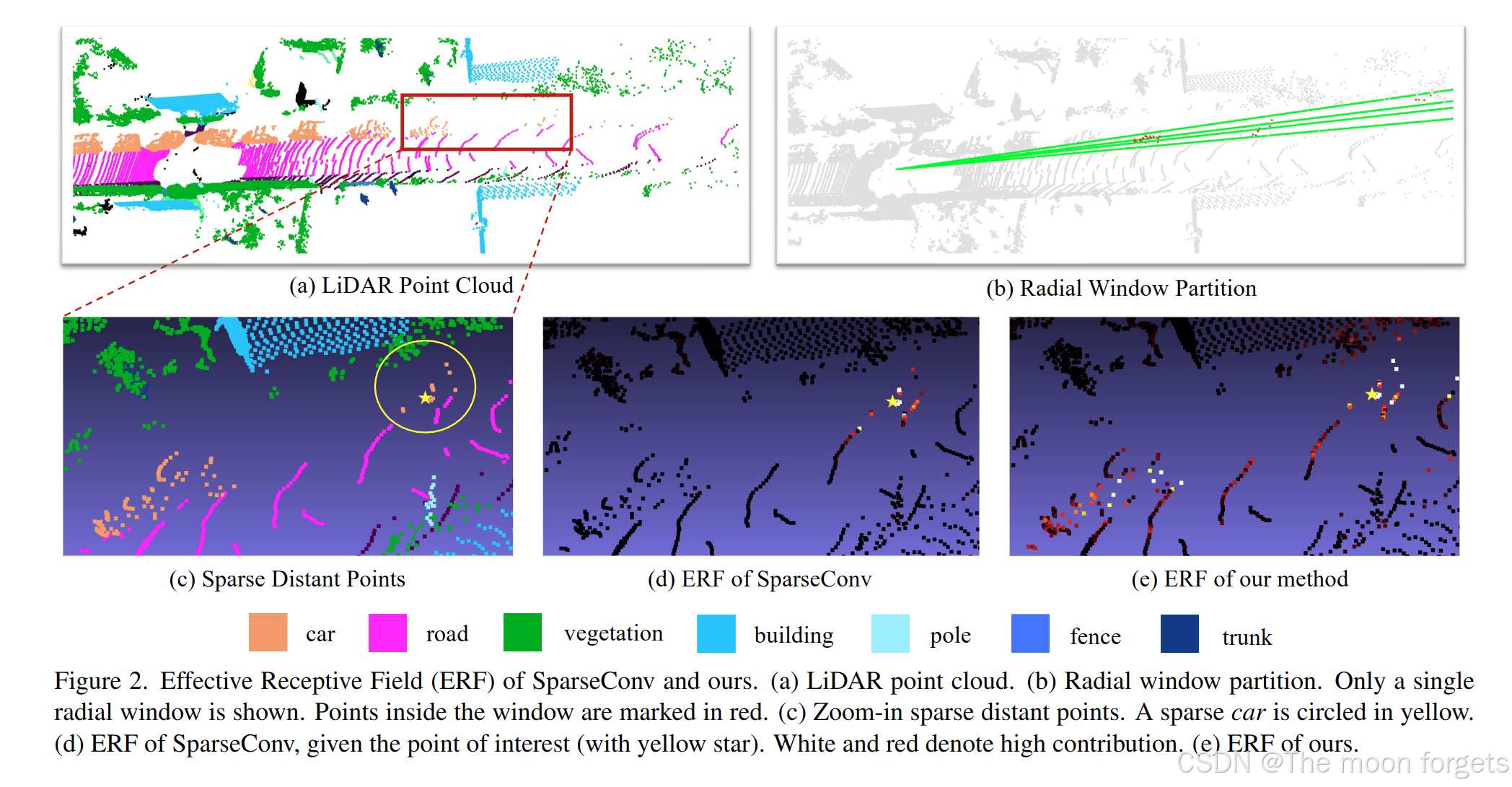
采用球坐标进行特征处理,以解决立方滑动窗口对远处稀疏区域特征提取不足的问题。提出了适配的exponential-spiltting PE 和 动态特征选取机制。
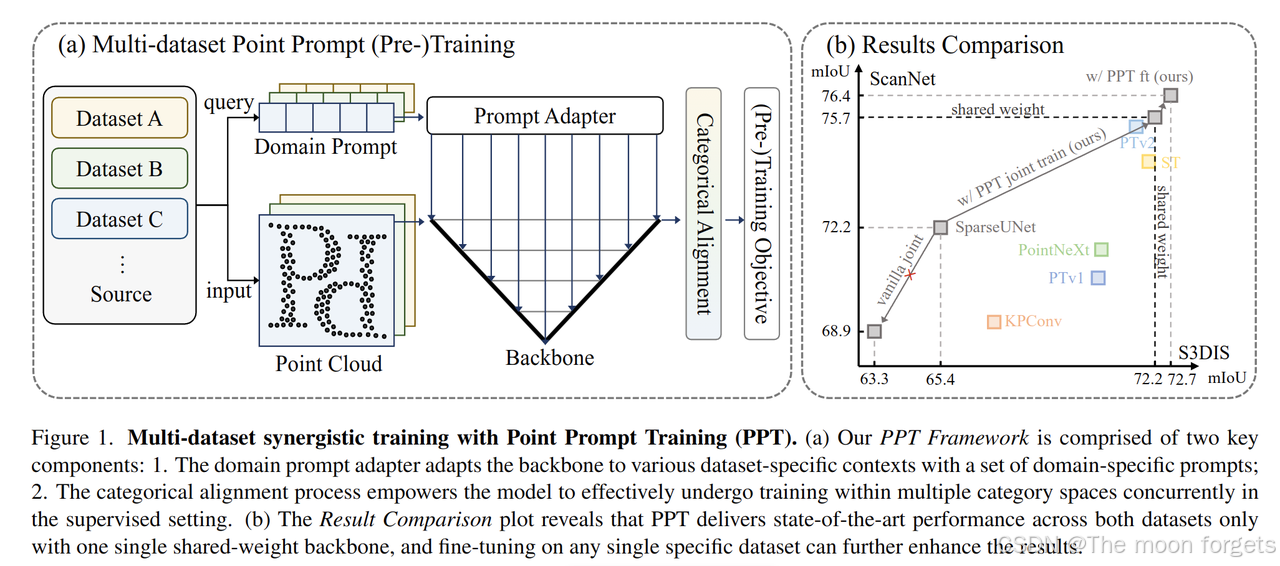
作者指出大规模3D点云d数据集的缺失限制了3D相关算法的发展,一种解决方法就是联合多个数据集训练一个模型。但是不同于图像,不同点云数据之前的差异是非常大的,直接联合训练反而会带来负面收益,因此本文提出了Point Prompt Training(PPT)来解决这一问题。