




- @uncle_gy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
累计BP和标准BP标准BP算法每次仅仅针对一个训练样例进行更新更新权值和阈值,参数更新非常频繁,而且不同样例的更新效果可能出现“抵消”的现象。累计BP算法累计误差:E=1m∑k=1mEkE=\dfrac{1}{m}\sum_{k=1}^{m}E_k直接针对累计误差最小化,再读取整个训练集DD一遍之后才对参数进行更新,对参数更新的频率会比标准BP算法低好多。但是累计误差在下降到一定程度之后
训练集上的误差使用EE表示神经网络在训练集合上的误差,则EE是关于连接权值w\mathbf{w}和阈值θ\theta的函数。最优对w∗\mathbf{w}^*和θ∗\theta^*若存在ϵ>0\epsilon\gt0使得,∀(w;θ)∈{(w;θ)∣||(w;θ)−(w∗;θ∗)||≤ϵ},\forall(\mathbf{w};\theta)\in\left\{(\mathbf{w};\the
训练集上的误差使用EE表示神经网络在训练集合上的误差,则EE是关于连接权值w\mathbf{w}和阈值θ\theta的函数。最优对w∗\mathbf{w}^*和θ∗\theta^*若存在ϵ>0\epsilon\gt0使得,∀(w;θ)∈{(w;θ)∣||(w;θ)−(w∗;θ∗)||≤ϵ},\forall(\mathbf{w};\theta)\in\left\{(\mathbf{w};\the
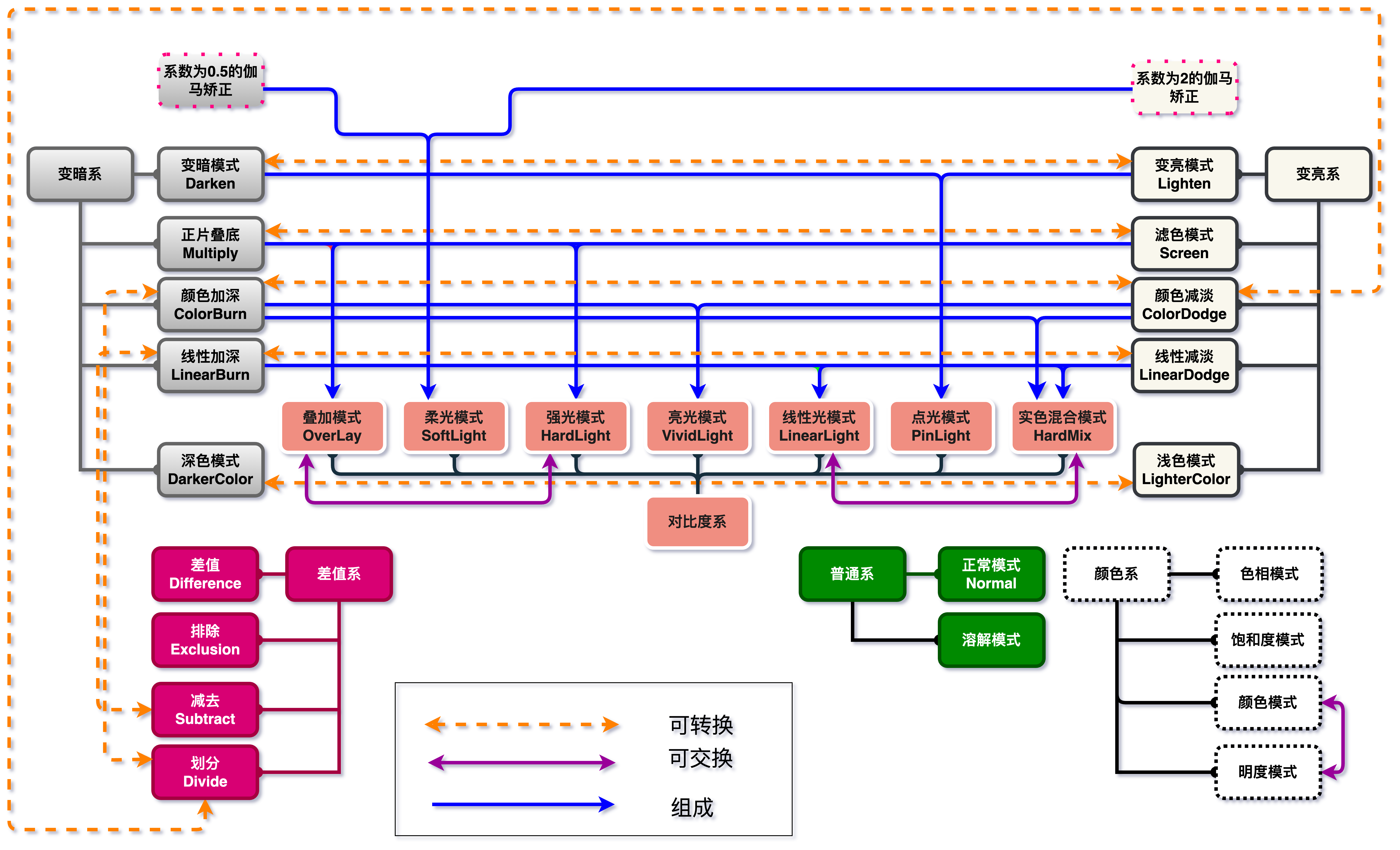
PS图层混合模式超详细解答-图层混合模式的原理☕前言本教程非常详细,请用心看完本教程如果有如何问题,欢迎评论区留言讨论本教程为了避免冗余,一些不必要的截图就省略了本教程只讨论8bit的情形下的混合未经许可,不可转载饮茶在一切开始之前,我们先泡一杯茶🍵泡一杯茶需要一杯开水,一袋茶叶,如果太苦我们还需要一些水来兑一下好的我们来温习一下泡茶的过程🍵1:我们准备一壶开水🍵2:我们准备一包茶叶,放多少
数据集是D={(x1,y1),(x2,y2),…,(xm,ym)}其中xi=(xi1;xi2;…;xid),yi∈RD=\left\{(\mathbf{x_1},y_1),(\mathbf{x_2},y_2),\dots,(\mathbf{x_m},y_m)\right\}\\\text{其中}\\\mathbf{x_i}=(x_{i1};x_{i2};\dots;x_{id}),y_i\
以《机器学习》第85页的图为例:使用包:\usepackage{tikz}代码:\documentclass[UTF8]{ctexart}\usepackage{tikz}\usetikzlibrary{shapes.geometric, arrows}\begin{document}\thispagestyle{empty}% 定义基本形状\tikzstyle{results}=[el
BP算法的伪代码代码\documentclass[11pt,UTF8]{ctexart}\usepackage[top=2cm, bottom=2cm, left=2cm, right=2cm]{geometry}\usepackage{algorithm}\usepackage{algorithmicx}\usepackage{algpseudocode}\usepackage{amsm
原文地址:https://en.wikipedia.org/wiki/Matrix_calculus注:不要把它和几何运算或者是向量运算混淆前言:在数学中,矩阵微积分是进行多变量微积分的一种特殊符号,特别是在矩阵的空间上。 它将关于许多变量的单个函数的各种偏导数和/或关于单个变量的多变量函数的偏导数收集到可以被视为单个实体的向量和矩阵中。 这大大简化例如找到多元函数的最大值或最小值,以及求解微分
原文地址:https://en.wikipedia.org/wiki/Matrix_calculus#Other_matrix_derivatives翻译:part1:http://blog.csdn.net/uncle_gy/article/details/78861467part2:http://blog.csdn.net/uncle_gy/article/details/78871515pa
前言又是关于机器学习那本书里的插图问题,里面有一些函数图形。现在看看怎么使用latex把它们画出来。这就是《机器学习》周志华,第98页的两个函数图像,貌似树上的坐标轴是不正确的,第二张图的横坐标应该扩大10倍,才有那种效果。使用到的包:\usepackage{tikz}示例代码:\documentclass[11pt,UTF8]{ctexart}\usepackage{tikz}\begin