- @u013517797
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文详细介绍了在阿里云控制台获取通义千问(Qwen)模型APIKey的操作流程。首先需要实名认证的阿里云账号,通过搜索或直接访问进入大模型服务平台百炼(sfm)控制台。关键步骤是创建APIKey时立即复制以"sk-"开头的密钥字符串,关闭后将无法再次查看。建议验证密钥状态并遵循安全规范,避免硬编码和泄露风险。获取APIKey是调用通义千问模型的必要前提,完成后可配置到开发
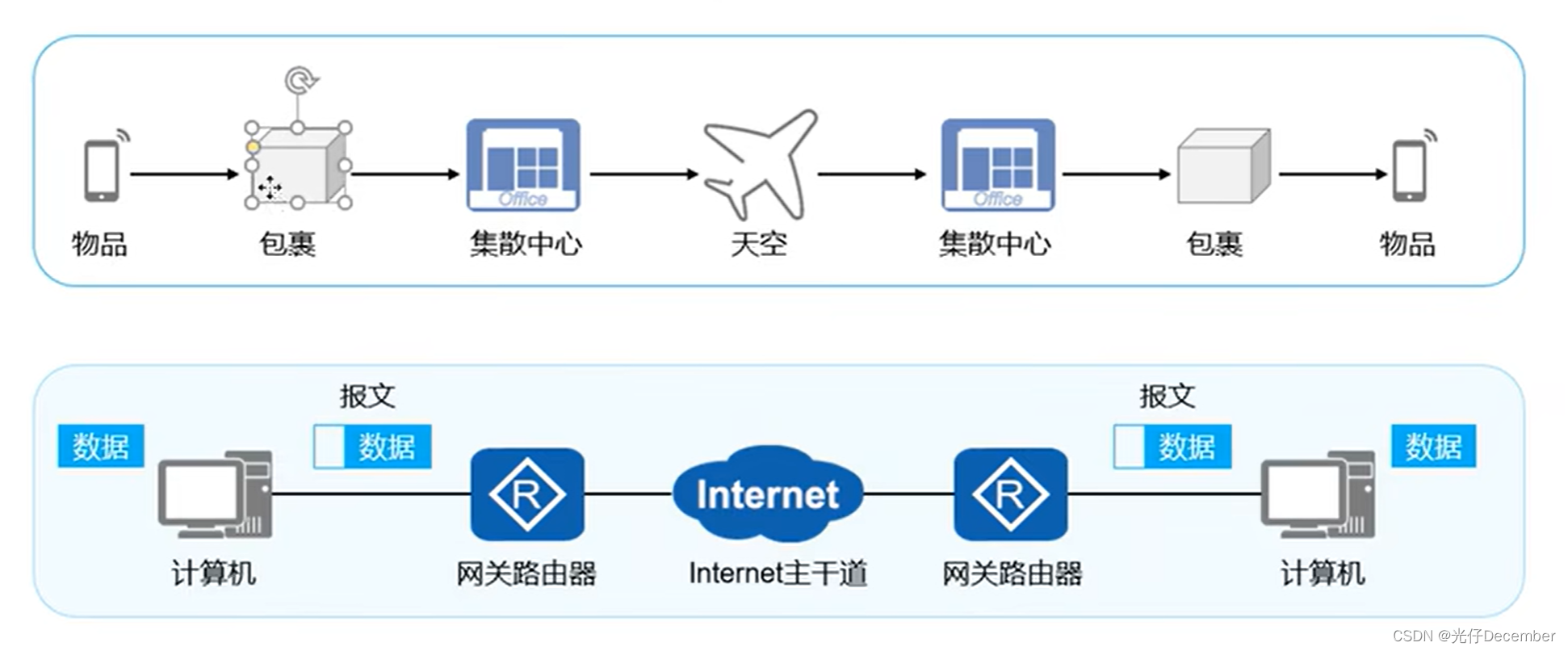
该系列为华为HCIA认证的基础课程学习总结,参考视频为众元教育。通信,是指人与人、人与物、物与物之间通过某种没接和行为进行的信息传递与交流。网络通信,是指终端设备之间通过计算机网络进行的通信。日常使用的各种APP、网游、微信聊天、网页浏览都属于网络通信的过程。网络通信需要网卡、交换机、路由器、无线设备等硬件,也需要TCP/IP协议等软件共同完成。
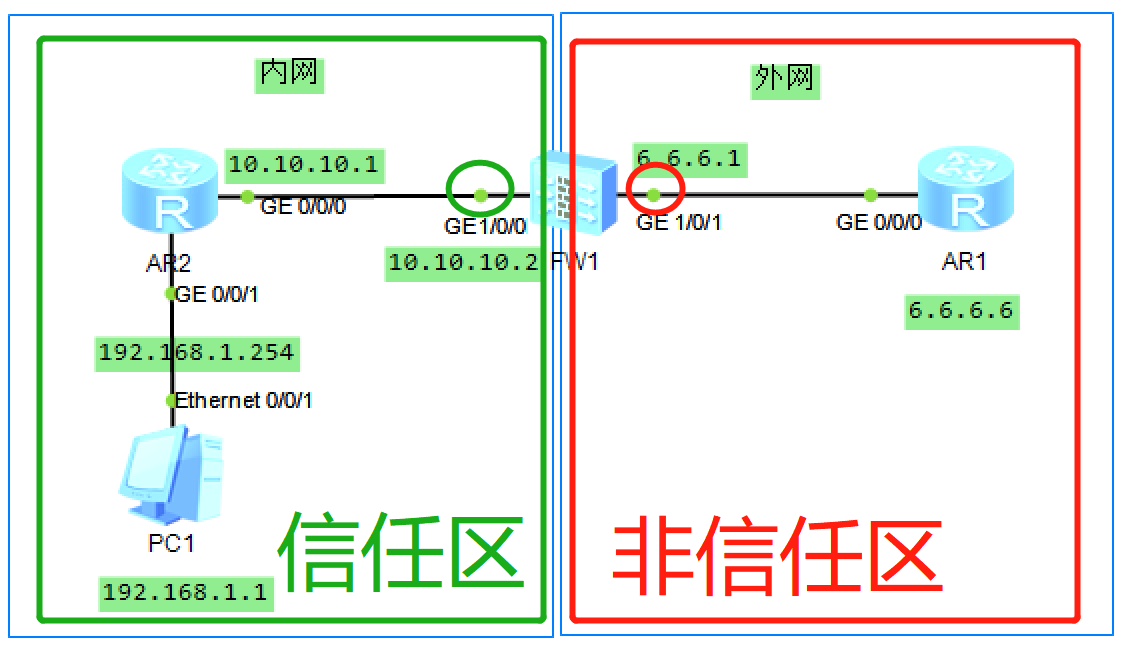
本篇我们来讲解防火墙的基础知识以及相应的实操案例。
摘要:本文详细介绍了在阿里云控制台获取通义千问(Qwen)模型APIKey的操作流程。首先需要实名认证的阿里云账号,通过搜索或直接访问进入大模型服务平台百炼(sfm)控制台。关键步骤是创建APIKey时立即复制以"sk-"开头的密钥字符串,关闭后将无法再次查看。建议验证密钥状态并遵循安全规范,避免硬编码和泄露风险。获取APIKey是调用通义千问模型的必要前提,完成后可配置到开发
本文介绍了SpringAIAlibaba(SAA)环境搭建的核心要点。强调版本选型的重要性,错误的版本组合会导致项目失败。文章提供了2026年推荐的"黄金组合":JDK17+SpringBoot3.5.x+SAA1.1.2.0,并解释了SAA独特的四段式版本号规则。通过实战演示,详细指导如何在IntelliJIDEA中创建项目、配置Maven、设置APIKey和环境变量,并提供
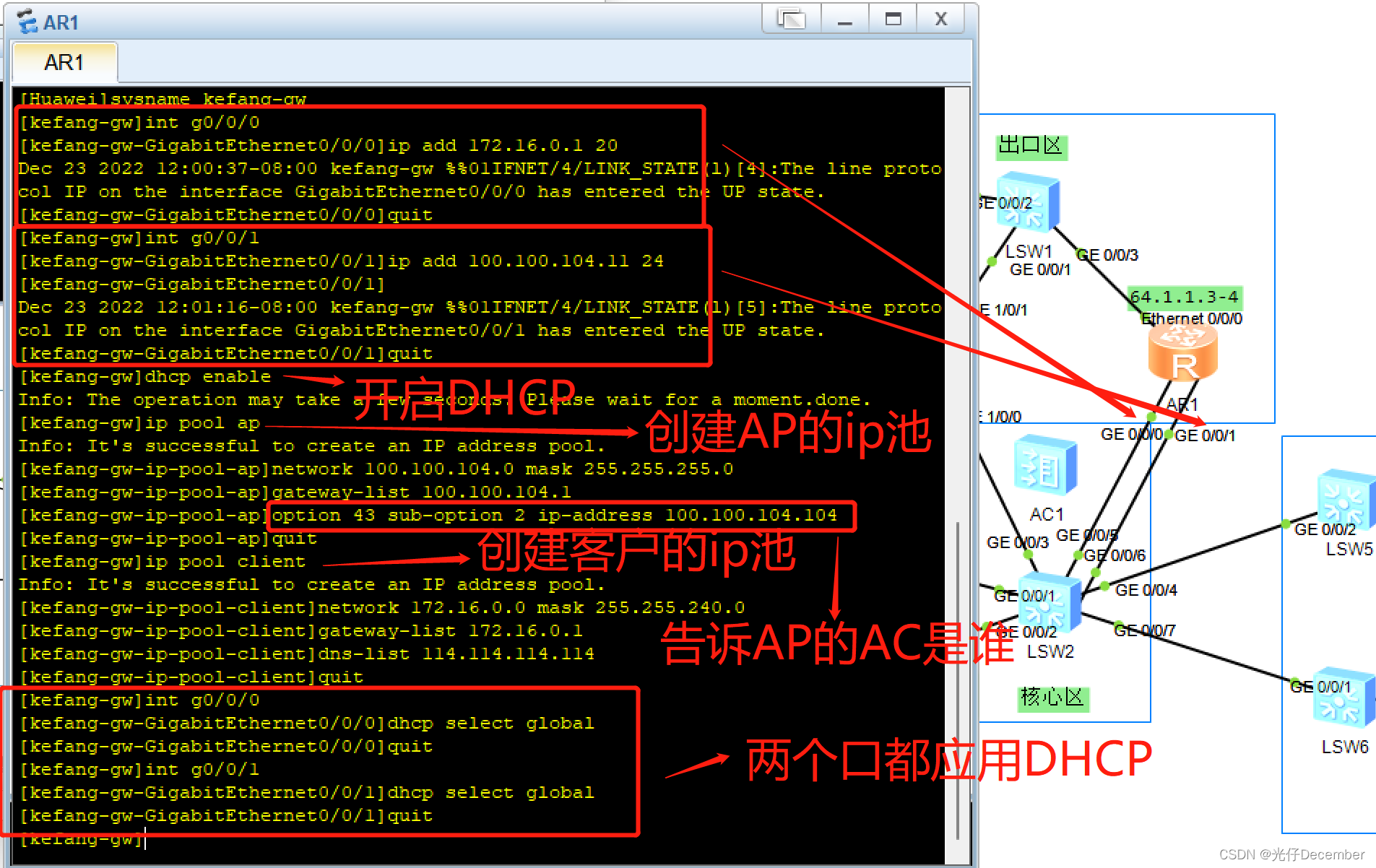
之前我们按照项目要求进行模拟拓扑的构建实操,完成了办公区部分的网络配置,本篇我们来继续完成其他区域的网络配置。
DSL(Domain Specific Language)提供了丰富的查询和结果处理能力。在实际应用中,我们经常需要对搜索结果进行排序、分页和高亮显示,以提升用户体验。本文将详细介绍如何使用Elasticsearch DSL对搜索结果进行处理,并结合酒店搜索的实际案例进行演示。
上一篇我们讲解了ElasticSearch的DSL搜索结果处理(排序、分页及高亮)。经过前面的学习,我们已经可以使用DSL来实现ElasticSearch文档查询和结果处理了。本篇我们就来学习使用Java的RestClient实现类似的功能。
上一篇我们完成了使用RestHighLevelClient创建索引库的代码实现,本篇将讲解如何判断索引库是否存在并删除它,以及如何对索引库中的文档进行增删改查操作。
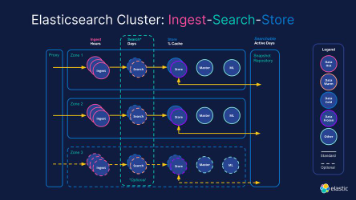
在Elasticsearch中,复合查询(Compound Query)是构建复杂搜索逻辑的核心工具。它允许将多个查询条件组合起来,灵活控制匹配逻辑和相关性算分。本篇博文将深入探讨BooleanQuery和FunctionScoreQuery的使用场景、原理及优化技巧,帮助大家解决实际业务中的搜索需求。