




- @u010834071
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1、当前连接数众所周知,CH 对外暴露的原生接口分为 TCP 和 HTTP 两类,通过 system.metrics 即可查询当前的 TCP、HTTP 与内部副本的连接数。ch7.nauu.com :) SELECT * FROM system.metrics WHERE metric LIKE '%Connection';SELECT *FROM system.metricsWHERE metr
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档@[TOC](文章目录)前言提示:这里可以添加本文要记录的大概内容:例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。提示:以下是本篇文章正文内容,下面案例可供参考一、Upsert Kafka Connector是什么?Upsert Kafka Connector允
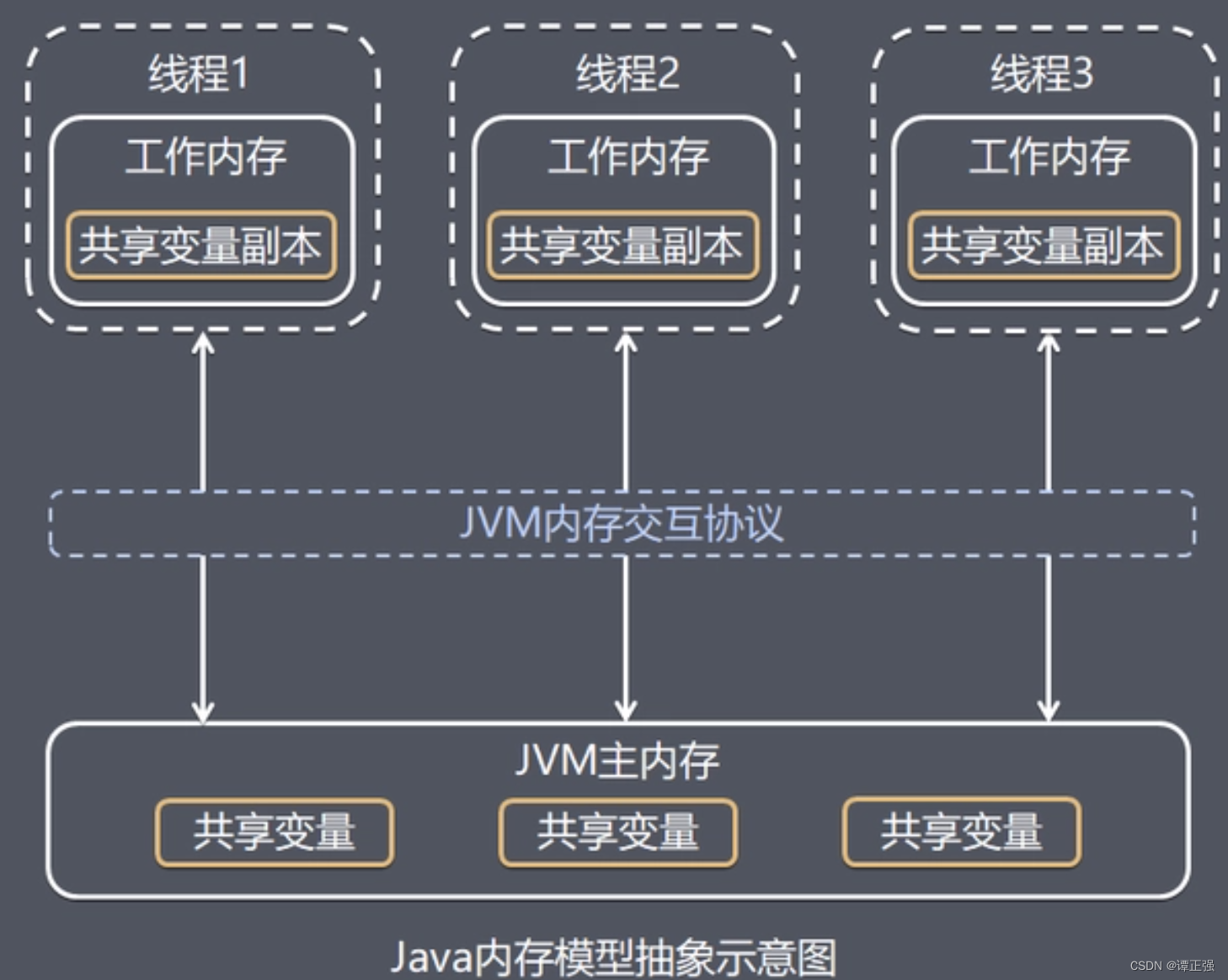
当我们提到 Java 的内存模型的时候通常会想到 JVM 运行时候的数据区域,比如包括线程私有的堆,方法区,线程共享的有本地方法栈,虚拟机栈,程序计数器。Java程序启动后,就会初始化这些内存的数据。但是这就是 Java 的内存模型了吗?Java的内存模型(Java Memory Model,JMM)是Java虚拟机(JVM)规范中定义的一种抽象概念,用于描述Java程序中各种变量的存储方式、访问
前言我们的作业是使用yarn来调度的,那么肯定就需要使用相关的命令来进行管理,简单的有查询任务列表和killed某一个正在运行中的任务。提示:以下是本篇文章正文内容,下面案例可供参考一、Yarn常用命令以下是基于yarn客户端使用命令行的方式进行:yarnapplication -list打印任务信息yarn applicaton -killapplicationId二、REST API1. 发送
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档@[TOC](文章目录)前言提示:这里可以添加本文要记录的大概内容:例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。提示:以下是本篇文章正文内容,下面案例可供参考一、Upsert Kafka Connector是什么?Upsert Kafka Connector允
前言我们的作业是使用yarn来调度的,那么肯定就需要使用相关的命令来进行管理,简单的有查询任务列表和killed某一个正在运行中的任务。提示:以下是本篇文章正文内容,下面案例可供参考一、Yarn常用命令以下是基于yarn客户端使用命令行的方式进行:yarnapplication -list打印任务信息yarn applicaton -killapplicationId二、REST API1. 发送