
写文章




- @thomas20
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
聊一个有趣的 Unicode 编码和 LLM Tokenization 问题
本次技术分享聚焦于大语言模型(LLM)输入输出中 Unicode 编码不一致的有趣现象。我们深入探讨了 Unicode 规范化(Normalization)的概念,解释了预组合字符和基本字符+组合字符的不同表示方式,以及常见的 NFC、NFD、NFKC 和 NFKD 等规范化形式。随后,我们阐述了为何不同 Unicode 编码的字符串在经过 LLM tokenizer 处理后可能得到相同的结果,关
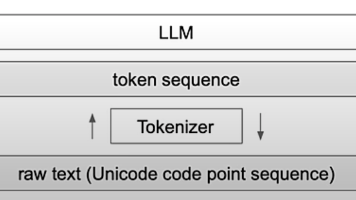
大语言模型推理的强化学习现状
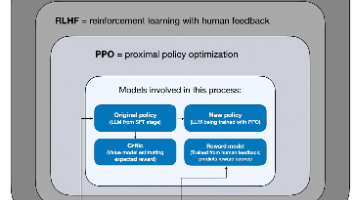
本文以深入浅出的方式,介绍了大语言模型推理中强化学习的最新发展,涵盖推理模型概念定义、RLHF、PPO、GRPO、RLVR 等核心算法与基础概念,分析当前强化学习在推理模型中的应用现状,并对后续研发方向提出推荐与展望,极具参考价值。
LLM基础课: 跟着大神 Andrej Karpathy 学习 Byte Pair Encoding
探索Tokenization的神秘世界:了解它如何塑造大型语言模型的理解力,特别是在处理多样化语言时的挑战与策略,揭示了为何LLM处理非英语文本时会遇到困难,以及如何优化这一过程。

到底了