- @tang7mj
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文记录了作者在开发爬虫功能时遇到的依赖包导入问题:尽管安装了beautifulsoup4包,但无法导入bs4模块。通过系统排查发现虚拟环境配置不当导致依赖安装路径错误,最终通过重新激活正确虚拟环境并重新安装依赖包解决了问题。文章详细描述了问题排查的全过程,包括环境检查、路径验证和解决方案,强调了虚拟环境配置的重要性,为开发者提供了类似问题的解决思路。

文章摘要: TypeScript是JavaScript的超集,通过引入静态类型系统和编译检查提升代码安全性与可维护性。安装后可通过tsc命令编译TS文件为JS,核心优势包括编译时类型检查(如避免参数类型错误)和IDE智能提示。大厂(如阿里、字节)广泛采用TS以解决大规模协作中的接口规范问题,典型案例显示TS能预防字段拼写错误、类型混淆等JS运行时风险。其核心价值在于用编译时约束换取更高的运行时稳定

摘要: VSCode源码自托管的关键在于解决Node版本、权限和启动顺序问题。核心步骤包括:1) 使用.nvmrc指定Node 22.17.0版本;2) 管理员终端运行npm ci安装依赖;3) 先执行npm run watch生成产物,再启动./scripts/code.bat。预编译二进制文件(如rg.exe)可降低环境复杂度。经验表明,90%的问题源于版本错配,其余10%通过权限管理和正确顺

2. 设[x]补=a7a6a5....a0,其中ai取0或1,若要x>-0.5,求a0,a1,a2,…a6的取值。

在强化学习中,Agent 想要学习如何在环境中做决策,找到能获得最大长期奖励的策略。我们需要一个严谨的框架来定义“状态-动作-奖励-转移”,这就是马尔可夫决策过程(MDP)。马尔可夫决策过程(MDP)符号含义状态空间,Agent 可能处于的所有状态动作空间,Agent 可执行的所有动作$P(s's,a)$$R(s,a)$奖励函数,执行 $a$ 后从 $s$ 获得的奖励$\gamma$折扣因子,用于

本文系统介绍了深度学习中的基础优化算法——梯度下降。首先从一维梯度下降入手,通过泰勒展开证明负梯度方向可使目标函数单调下降,并讨论了学习率选择的重要性,指出过大或过小的学习率分别会导致发散或收敛缓慢。接着扩展到多维情况,引入梯度向量概念。此外,讲解了牛顿法等自适应方法,分析其快速收敛特性及在非凸问题中的局限性,并探讨了预处理和线搜索等改进策略。最后强调梯度下降是现代优化算法(如Adam)的基础,并
..语义分割关注像素级别的图像内容解析;VOC2012 是经典入门数据集;标签使用颜色编码,训练前需转换为索引;图像与标签裁剪应同步处理;可通过 Dataset 封装 + DataLoader 组织训练流程。语义分割是众多应用(自动驾驶、医学、视觉智能剪辑)的核心技术;数据组织、增强、标签映射规范化,是大厂模型可复用的关键;主流工业系统都采用标准数据结构(如 VOC、COCO 格式)作为底层训练格

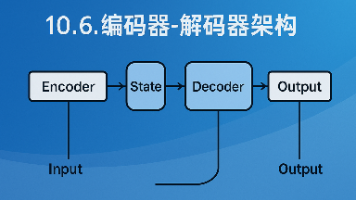
摘要:编码器-解码器架构是处理序列到序列任务的核心框架,通过编码器将变长输入压缩为状态向量,再由解码器自回归生成目标序列。该架构具有高度通用性,广泛应用于机器翻译、语音识别、文本摘要等场景。其核心优势包括信息压缩能力、生成灵活性及模块化设计。随着注意力机制的引入,有效解决了长序列信息丢失问题。在工业实践中,该架构已拓展至多模态应用,如视频字幕生成、跨语言迁移学习和图文生成系统,通过灵活组合不同编码
概念核心理解软间隔允许小部分样本出错,追求泛化而非完美分类松弛变量每个不满足约束的样本都有一个 ξᵢ,度量“出错程度”替代损失函数为了优化更容易,使用连续、凸的损失代替 0/1正则化统一目标为:“间隔 + 错误” 的最小化平衡稀疏性最终模型仅由少数支持向量构成,效率高。

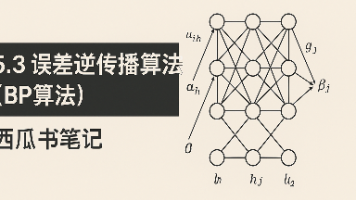
相比单层感知机,多层前馈神经网络(如图5.6(b)所示)具有更强的表达能力。但也因此,感知机的简单学习规则(如公式5.1)已无法胜任。BP算法应运而生,其本质是一种基于梯度下降法的链式求导机制,通过计算输出误差的梯度反向传播到各层神经元,进而更新网络参数。BP算法是当前神经网络最成功、应用最广泛的训练算法之一,也可用于递归神经网络等复杂结构的训练。