
戏谈DeepSeek V4:开源扔王炸,闭源三巨头都慌了!


温馨提醒:数据中心4件套(服务器、存储、网络、SSD全解系列)姊妹篇已全部发布,之前购买过“架构师技术全店资料打包汇总(全)(已持续更新至48本)”的读者免费发放全店更新(请在发货的汇总链接下载),或请凭借购买记录在微店留言获取(PDF阅读版本)。
2026年4月24日,大模型圈直接炸锅!DeepSeek 没搞预热、没开发布会,官微就一句话:DeepSeek-V4 预览版上线 + 直接开源,堪称AI界的 “不讲武德式突袭”。
这波操作直接把开源模型的天花板捅破,评分贴脸闭源三巨头(GPT5.4、Claude4.6、Gemini3.1),妥妥的地表最强开源大模型,今天咱就用唠嗑的方式,扒透这货到底有多狠!
一、先破两个洗脑误区,别被参数忽悠瘸了
先看 V4 的两款狠活,别被数字绕晕:
- V4-Pro:1.6T 总参数,稀疏激活 49B,1M 上下文拉满
- V4-Flash:284B 参数,稀疏激活 13B,同样 1M 上下文
误区 1:Flash 是 Pro 的缩水蒸馏版?
大漏特漏!俩都是独立预训练的 MoE 模型,只是规模、稀疏度不同,不是 “大哥减配版”。
误区 2:1M 上下文是可选开关?
想多了!两款默认全量 1M 上下文,服务端不搞长短模型区分,直接把长上下文焊死在标配里。
别觉得 1M token 是噱头,这玩意儿直接改写 AI 干活逻辑:
-
30 轮 Coding Agent 跑下来,几十万 token 起步,旧模型早把历史记录丢光,V4 全兜住
-
300 个文件、15 万行代码的中型项目,直接整仓扔进去,跨文件重构、找 bug 不遗漏调用点
-
200 页法律合同、500 页学术论文,不用切块摘要,直接全文啃透做推理
以前长上下文是 “炫技”,现在 V4 把它变成AI 干活的刚需标配。
二、核心狠活:不堆参数堆架构,把 Transformer 按在地上摩擦
传统 Transformer 遇到 1M 上下文,直接原地崩盘:Prefill 阶段计算量平方级暴涨,Decode 阶段 KV 缓存吃爆显存,深层网络还容易训练崩。
DeepSeek V4 直接搞了三大底层革命,把这些坑全填了:
1. mHC 多流约束残差:给模型装 “智能电梯调度”
标准残差就像一栋楼只有一部电梯,浅层、深层信息挤在一起,还均等分配贡献,越深层越乱,训练深了还容易梯度消失 / 爆炸。
mHC 直接升级成多电梯 + 智能调度 + 运营规范:
-
多流并行:修 N 条独立通道,浅层、深层信息不打架
-
权重调度:给每层贡献加 “阀门”,重要层多给算力,没用的少占资源
-
双随机矩阵约束:给调度系统上规矩,杜绝电梯超载、空载,从根上解决训练不稳定
简单说:模型能做更深、更大,还不炸算力、不跑偏。
2. CSA+HCA 混合稀疏注意力:AI 版 “略读 + 精读”
标准注意力要算每对 token 的关联,1M 上下文直接算爆显卡,这也是为啥很多模型长上下文 “能用但贵到哭”。
V4 搞了两套注意力组合拳,直接把计算量砍到膝盖:
- CSA 压缩稀疏注意力:像荧光笔划重点,把连续 token 压缩成 “纪要”,再用闪电索引挑最相关的,只算重点
- HCA 高度压缩注意力:像先看目录,把大段文本压成 “宏观块”,先定位关键大块,再用 CSA 精细化算
一套 “海选大块->精选重点->精确计算”,KV 缓存直接砍 90%,推理算力省 73%,1M 上下文跑得比旧模型 128K 还丝滑。
3. Muon 优化器 + 训练骚操作:让模型学又快又稳
以前训练大模型,梯度乱晃、Logits 爆炸,收敛慢还容易崩。V4 直接换 “学霸学习法”:
-
梯度正交化:把梯度方向解耦,各学各的,不互相干扰,收敛快一倍
-
前置 RMSNorm:给 Q、K 先做归一化,杜绝个别值 “嗓门太大” 掩盖其他信息,训练稳如老狗
-
FP4 量化感知训练:训练时就适应低精度,部署后省显存、提速,还不丢精度。
三、工程细节拉满:让显卡吃饱,不摸鱼
光有架构不够,工程优化才是落地关键,V4 这波直接把硬件利用率拉满:
- 细粒度计算通信重叠:MoE 模型算和通信同步搞,消除闲置 “气泡”,显卡不摸鱼
- TileLang 算子神器:不用苦写 CUDA,简洁代码就能跑出超手工优化的性能,还能适配国产硬件
- 批无关 + 计算确定性:不管 batch 怎么切,输出结果比特级一致,部署不翻车
- 定制 KV 缓存:适配 CSA/HCA 异构缓存,还能持久化存常用 prompt,重复请求不重算。
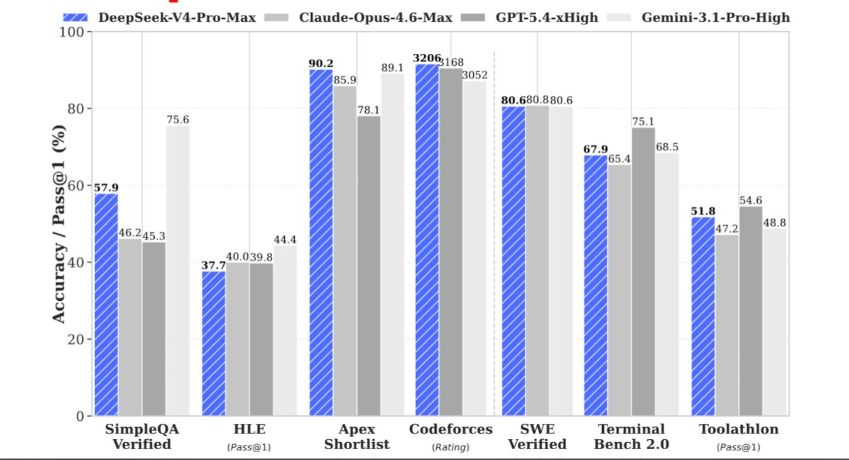
成绩单亮瞎眼:开源天花板,闭源都汗流浃背
别光说技术,看实打实的战绩:
-
编程:SWE Verified 80.6%,Codeforces 3206 分,碾压一众开源,比肩闭源顶流
-
长文本:MRCR 1M 拿 83.5,开源最高,啃百万 token 文档无压力
-
Agent、数学、推理全维度杀入第一梯队,中文能力直接登顶国产模型第一。
四、总结:V4 不是升级,是开源大模型的革命
DeepSeek V4没搞新花样,就是把 mHC、CSA/HCA、Muon、TileLang 这些技术,精雕细琢后拼成一套闭环系统。
它证明了:开源模型不用追着闭源跑,靠架构创新、工程极致优化,照样能摸到顶流水平,还把长上下文、高效率打成开源标配。
简单总结:闭源慌了,开源赢麻了,AI 圈从此多了个不讲道理的狠角色!
相关阅读:
宕机背后的技术博弈:DeepSeek V4隐身测试与难产之谜
全球AI收费模式变天:Tokens失宠,集体转向PTU模式!
超节点三国杀:以太网、InfiniBand、NVLink协议终极对决
DeepSeek-V4杀到2分钱百万Token:一场由昇腾 950PR 撑腰的价格革命
![]()
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。


免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)