- @sweet_ran
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出了一种混合搜索架构HybridDeepSearcher,通过构建HDS-QA数据集教导模型动态结合并行查询与显式证据聚合,解决了现有深度搜索代理的"扩展性悖论"。实验表明,该方法在多个高难度基准上性能显著提升,且是唯一能随搜索次数和调用量增加而持续改进的模型。

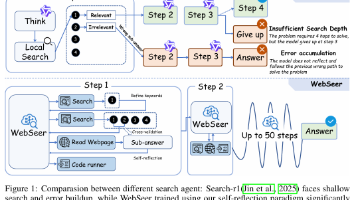
本文提出WebSeer框架,通过自我反思强化学习(SRRL)解决搜索代理"浅层搜索"问题。WebSeer采用"搜索-反思-修正"闭环机制,在HotpotQA和SimpleQA上分别达到72.3%和90.0%的SOTA准确率。核心创新包括:1)构建包含多轮反思的错题本数据;2)设计指数衰减奖励函数,平衡修正次数与效率;3)集成搜索引擎、网页阅读器和代码执行器等
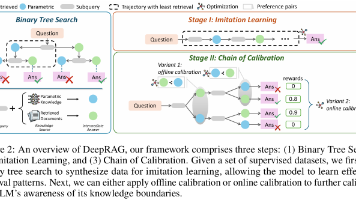
清华大学与智谱AI团队提出DeepRAG框架,创新性地将检索操作深度融入大模型的思维链推理过程。该方法通过特殊标记<search>实现"边想边查"的动态检索机制,在生成思维链时自主判断检索时机与内容。实验表明,DeepRAG在HotpotQA等多跳推理任务上显著优于现有方法,检索效率提升30%的同时准确率提高10%。该研究突破了传统RAG"检索-推理割裂&
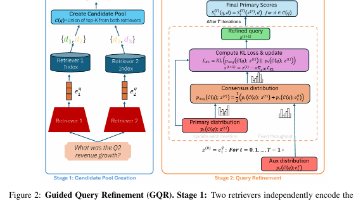
摘要:斯坦福大学与IBM Research团队提出GQR(Guided Query Refinement)框架,解决多模态文档检索中视觉中心模型(如ColPali)资源消耗大、延迟高的问题。GQR通过测试时优化,利用轻量级文本检索器动态修正主视觉模型的查询嵌入,实现跨模态引导。实验表明,GQR使7B参数模型性能媲美3B+超大模型,同时推理速度提升14倍,显存占用降低54倍。该方法突破了传统混合检索
摘要: 拉普拉斯平滑(加一平滑)是解决零概率问题的统计技术,通过给所有事件加1次计数,避免概率为0的情况。核心公式为$P_{smooth}(x)=\frac{计数(x)+1}{总计数+V}$,其中$V$是词汇表大小。例如,在美食推荐中,即使某菜品未被点过(计数为0),平滑后仍会获得微小概率(如1/104),提升模型泛化能力。该方法广泛应用于N-gram语言模型和文本分类,但存在过度稀释概率的局限性
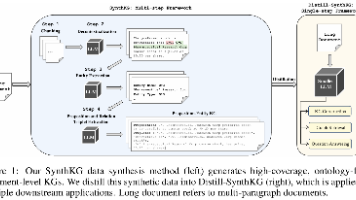
摘要:文档级知识图谱(KG)构建面临大模型成本高、小模型效果差的困境。Salesforce Research等团队提出SynthKG方法,通过分块、去语境化和结构化提取生成高质量合成数据,并蒸馏为Distill-SynthKG,使8B小模型单步推理即可超越70B大模型的KG构建质量。实验显示,该方法在覆盖率、检索精度和多跳问答上均达SOTA,成本仅为传统方法的3%。核心创新包括文档级KG合成流水线
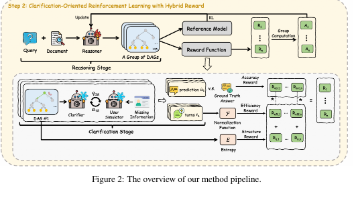
首创图引导的主动澄清框架首次将条件推理 DAG引入 RAG 澄清任务,将非结构化的对话问题转化为结构化的图遍历问题,确保了逻辑的完备性。理论驱动的动态剪枝算法证明了 DAG 表示的逻辑完备性,并设计了OrO(r)Or复杂度的动态遍历算法,从根本上解决了多条件场景下的交互效率瓶颈。信息转换效率奖励机制创新性地提出基于熵的结构质量奖励 (RηR_{\eta}Rη),量化了中间提问对最终结论的区分度,