
写文章




- @sqhnb521
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
KV Cache 详解:大模型推理的核心优化技术
KVCache是Transformer模型推理优化的关键技术,通过缓存历史token的Key和Value向量避免重复计算,将推理复杂度从O(n²)降到O(n)。其核心原理是在生成每个新token时,只需计算当前token的K/V,历史token的K/V从缓存读取。虽然会占用额外内存(如LLaMA-7B模型约需2.1GB),但显著提升推理速度。主要优化技术包括分页管理(PagedAttention)
Transformer 解析:从原理到应用,一篇看懂 “注意力即一切“
Transformer模型是2017年谷歌团队在《AttentionIsAllYouNeed》论文中提出的革命性深度学习架构。它完全基于注意力机制,解决了RNN无法并行计算和CNN难以捕捉长距离依赖的问题,成为NLP、CV等领域的核心模型。Transformer通过编码器-解码器结构实现序列转换,其核心是多头自注意力机制,让模型能直接关注任意位置的相关信息。该模型在机器翻译等任务中表现优异,训练速
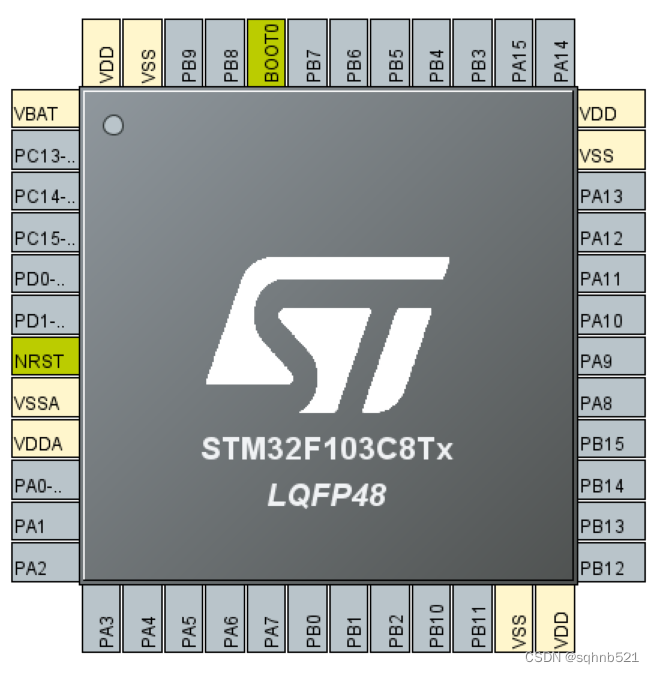
STM32F103C8T6与C6T6的区别
STM32C8T6和C6T6的区别
到底了