




- @smartcat2010
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
可用性优先于性能 (PyTorch的主要目标是可用性,次要目标是合理的性能。避免过早实施严格的用户限制,以保持灵活性,支持构建在PyTorch抽象之上的研究人员。PyTorch以可用性为先,避免过早采用限制性规则,以确保用户体验的完整性和灵活性。简单胜于易用PyTorch倾向于提供简单和明确的构建模块,而不是易于使用的API。明确比隐式更好,简单比复杂更好。通过暴露简单和明确的构建模块,PyTor

NCCL和custom allreduce(应该就是指one-shot和two-shot以及half-bufferfly那些,小数据量通信情况下,降低延迟用的)原理就是新到request的prefill,不阻塞正在decode的request。和continous batching一起使用时,为什么加速比和qps有关?qps上来以后,延迟能有明显的优化。
传统LLM(比如早期GPT):输入 → 立即生成输出(一步到位)输入 → 内部多步推理(可能几十步) → 再输出答案。
跳过权限确认输入:
减少max_num_seqs或max_num_batched_tokens。减少一个batch里的请求、token个数,从而减少KV cache占用。显存不够的时候,某些request会被抢占。其KV cache被清除,腾退给其他request,下次调度到它,重新计算KV cache。可以查看VLLM自带的Prometheus指标,查看抢占的请求数量。- 增大gpu_memory_utilizat

原文今天我们来讲下最近比较博眼球的联邦学习。应该很多人听过但是始终都没懂啥是联邦学习?百度一下发现大篇文章都说可以用来解决数据孤岛,那它又是如何来解决数据孤岛问题的?对于联邦学习,大部分文章还都处于其学术分享会的报道阶段,并未详细介绍联邦学习的实现方法,难以理解其真容,本篇文章将从技术角度介绍联邦学习。1、联邦学习的背景介绍近年来人工智能可谓风风火火,掀起一波又一波浪潮,从人脸识别、活...
神经网络预测推理---TensorRT: (比Tensorflow的推理快20倍)1. Kernel融合: 横向融合(例如1*1卷积等), 纵向融合(卷积+bias+Relu),消除concatenate层(预分配输出缓存,跳跃式的写入);2. 量化成FP16或者INT8: 减少显存占用,加快推理速度;3. Auto-Tuning:例如,对于卷积计算有若干种算法,TensorRT会...
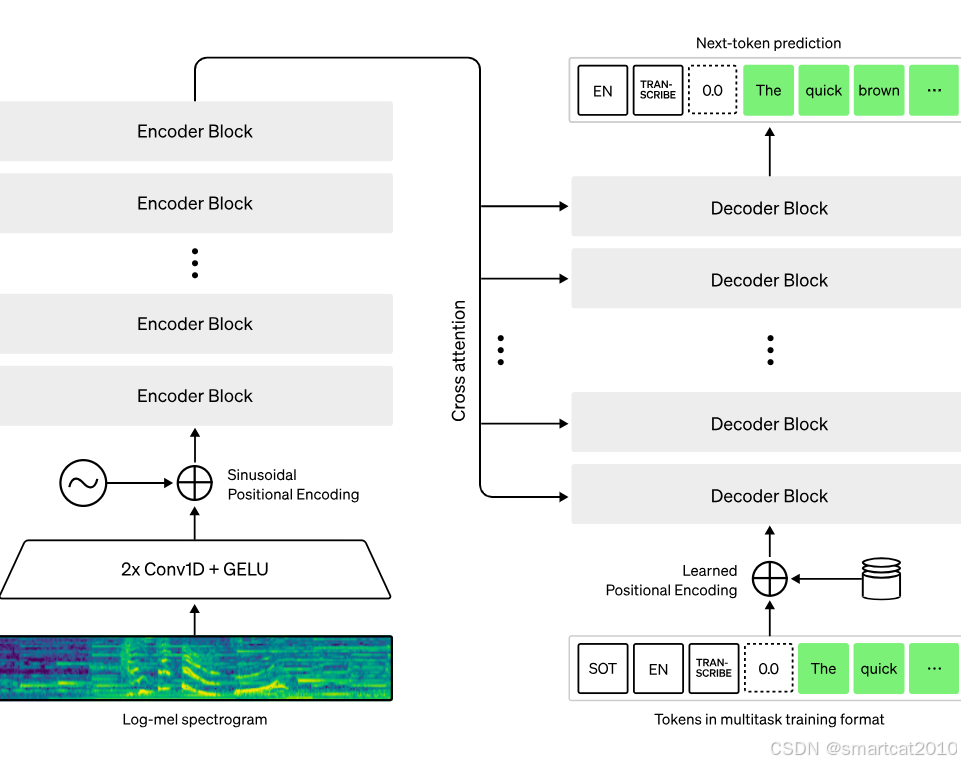
Encoder-Decoder结构。68万小时的监督数据,做的训练。
APC技术,遇到新prompt和老prompt前缀完全相等的,则复用老prompt的KV cache,避免重新计算。3. 只要前面有1个字符不同,后面完全相同的部分,也不能被视为公共前缀。2. prefill公共前缀较长,且decode output较短时,KV cache复用的威力才能发挥出来。则把长文档放到前面,可以复用KV cache。enable_prefix_caching,prompt

每个SM block上的Q,负责和所有K和所有V进行计算,得到对应的结果。但是,在decoding阶段,因为Query的seqLength=1,且batchSize=1,因此SM block数目无法都利用上。缺点:最后需要将不同SM block上的中间结果,进行通信,进行归一化的softmax和结果Reduce。在prefill阶段,seqLength*batchSize*Heads足够多,所以每
