




- @sinat_33455447
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
opencompass使用自定义接口和自定义数据集进行评测

本次应用的目的是拿nginx做服务器的负载均衡,而且提供的服务已用docker进行部署,该docker提供访问的端口有两个,分别对应不同的服务。因此首先需要查看docker映射的端口,然后通过修改upsteam,location,proxy三个模块达到目的。1.查看docker服务映射的端口netstat -ltunp #查看端口如上图所示,本机的docker服务端口是...
前言,最近在搞大量数据插入MySQL的时候悲催的发现速度越来越慢,因为我的数据来多个源,使用流式更新,而且产品要求在这个表里面不能有数据重复,划重点!衡量数据是否重复的字段是文本内容,字段类型是text,…那么问题来了,如何在千万级数据量实现去重插入呢?而且要快!自杀式做法1.管它重复不重复,先插入了再说2.使用group by 先对不能重复的字段进行分组,在用一个having coun...
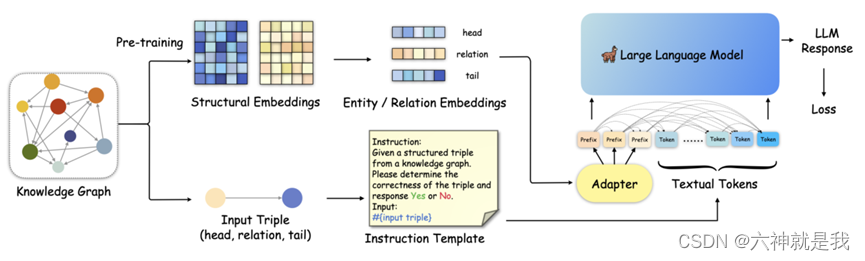
本文的研究目标是探索如何将结构信息融入大型语言模型(LLM),以提高其在**知识图谱补全**任务中的表现。具体来说,是通过结构嵌入预训练和知识前缀适配器(KoPA)来实现结构信息的有效利用。
论文介绍了 "ReAct" 范式,该范式旨在融合推理和行动的功能,通过让大型语言模型(LLMs)生成既包括言语推理轨迹又包括行动序列的输出,解决多种语言推理和决策任务。这种方法允许模型在与外部环境(如Wikipedia)交互时动态地进行推理和调整计划。

论文的目标是通过对工具学习的“为什么”和“如何”这两个方面进行探讨,来全面理解LLMs与工具结合的过程及其优势。具体而言,论文首先从工具集成的益处和工具学习范式固有的优势两个方面探讨了工具学习的意义,其次从任务规划、工具选择、工具调用和响应生成四个阶段,系统回顾了工具学习的实现方式。
