




- @sinat_27016095
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Kafka Connect支持两种运行模式:独立模式和分布式模式。独立(Standalone)模式所有组件运行在单个进程中适合开发、测试或小规模部署配置通过属性文件静态定义不提供自动容错和扩展能力分布式(Distributed)模式多个Worker节点组成集群支持自动负载均衡和故障转移通过REST API动态管理配置提供水平扩展能力和高可用性实践建议:虽然独立模式配置简单,但在生产环境中,强烈推荐
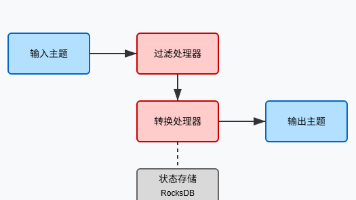
在Kafka Streams中,一切都以"流"为中心。流是一个无限的、持续的事件序列。想象一条永不停歇的河流,数据像水一样持续流动,你的应用则是沿途建立的各种处理站,对流经的水进行过滤、转换或聚合。数据源 --> [过滤] --> [转换] --> [聚合] --> 数据目的地Kafka Streams采用了处理-保存的流处理范式,每条记录都会被独立处理,应用的状态会在处理过程中被保存。📌核心理
MirrorMaker 2.0是Kafka官方提供的跨集群复制工具,它基于Kafka Connect框架,支持主动-主动或主动-被动的复制模式。相比第一代MirrorMaker,MM2提供了更简便的配置和更强大的功能,包括主题命名自动转换、消费者组偏移量同步等。代码示例:配置MirrorMaker进行跨集群备份# 集群别名# 为source→target配置MirrorMakerprimary->
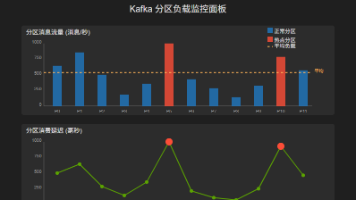
用户可以实现自己的分区策略,根据业务需求灵活控制消息分布。从Kafka 2.4版本开始,默认分区策略变成了粘性分区器(StickyPartitioner),它在保持均衡分布的同时,尽量减少producer批次的数量,提高效率。接下来,让我们看看分区不均衡问题是如何影响Kafka系统的正常运行的。在处理复杂业务场景时,Kafka内置的分区策略往往无法完全满足需求。这时,我们需要开发自定义分区策略,就
通过本文的探讨,我们深入了解了Kafka在消息保证方面的核心机制——幂等性、事务与精确一次处理。这些机制就像是构建可靠分布式系统的基石,为我们提供了应对复杂场景的有力工具。
在部署生产环境前,请检查以下关键配置:✅可靠性配置acks设置符合业务可靠性需求启用幂等性(enable.idempotence=true)防止重复为关键业务设置足够的重试次数考虑是否需要事务支持✅性能配置batch.size和linger.ms根据吞吐量需求调整选择合适的压缩算法buffer.memory设置适当,避免OOMmax.in.flight.requests.per.connectio
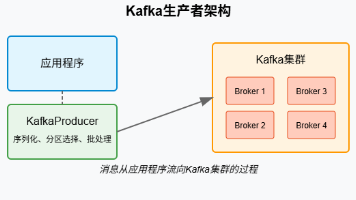
在当今微服务架构蓬勃发展的时代,消息中间件已成为各系统间可靠通信的关键纽带。Apache Kafka凭借其出色的高吞吐量、可扩展性和持久化能力,已然成为分布式系统中不可或缺的基础设施。而SpringBoot作为Java生态中最流行的应用开发框架,其简洁的配置方式和丰富的生态系统,使得与Kafka的整合变得异常优雅。当SpringBoot与Kafka联手,我们能够轻松构建出响应迅速、松耦合且高度可扩
在大数据时代,Kafka作为分布式流处理平台的"高速公路",承载着企业核心业务数据的流转。随着数据安全法规(如GDPR、CCPA等)的日益严格,仅仅关注Kafka的性能和可用性已远远不够——安全机制已成为Kafka部署的"必选项"而非"附加项"。就像我们不会把家门钥匙随意放在门外的花盆下,企业的数据资产同样需要严密保护。遗憾的是,我在咨询过的许多企业中,Kafka集群仍处于"裸奔"状态——没有认证
*** 自定义副本分配策略 - 机架感知且优先选择高性能节点*/// 高性能节点列表@Override// 按机架分组broker// 优先从高性能节点选择Leader副本// 为剩余副本选择不同机架的broker// 选择Leader副本,优先考虑高性能节点// 实现Leader选择逻辑// 如果没有高性能节点可用,退化为随机选择// 选择剩余副本,尽量分散在不同机架// 实现剩余副本选择逻辑,
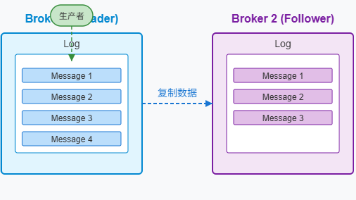
核心概念:深入理解了Topic、Partition、Producer、Consumer Group等基础概念高级特性:分析了Kafka Streams、事务支持、配额管理等进阶功能性能调优:分享了生产者、消费者和Broker端的性能优化经验踩坑经验:总结了消息积压、集群扩容、消息乱序等常见问题的解决方案高可用架构:探讨了多数据中心部署、容灾备份和Kubernetes部署最佳实践实际案例:分析了日志
