写文章




- @shizheng_Li
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
C++ Lambda 表达式中的 [ ] —— 捕获列表详解
lambda表达式
用 jose 正确处理 JWT:签发、验签、过期与密钥管理
服务端要怎么记住这个用户已经登录过了?
PostgreSQL:世界上最先进的开源关系型数据库
postgresql学习
Triton 核心组件之优化管道:让代码“自动跑得快“的幕后功臣
文章摘要: Triton优化管道是提升GPU内核性能的核心组件,它将高级TTIR转换为高效的TTGIR。关键优化Pass包括:Coalesce Pass通过调整数据布局实现访存合并,AccelerateMatmul Pass利用Tensor Core加速矩阵运算,Prefetch Pass实现计算与数据搬运重叠,以及CombineSelect Pass融合条件操作。
探索 Python 的 Glob 模块:简单高效的文件搜索工具
Python 的glob模块是一个简单而强大的工具,能够帮助开发者快速查找和处理文件。
深入解析 grep:Claude Code 为何选择这个古老工具?
它通过正则表达式(Regular Expression,简称 regex)在文件或输入流中查找匹配的行,并将结果输出。grep 的核心功能是简单、高效、精确的文本匹配,广泛应用于日志分析、代码搜索和数据处理。
Claude Code使用的代码搜索神器:剖析“Search(pattern: ... )”命令的秘密
这不是原生 Linux 命令,而是 AI 工具链(如 Anthropic 的 Claude AI 或类似代码助手)中一个封装的“搜索函数”
Electron 运行时架构详解:Node.js 主进程 + Chromium 浏览器进程
Electron 的 Node.js 主进程 + Chromium 渲染进程架构巧妙地将 Web 开发扩展到桌面,实现了“一次编写,到处运行”的理念。
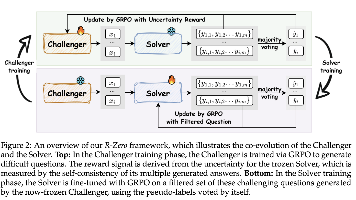
R-Zero:从零数据自进化推理大语言模型
R-Zero: Self-Evolving Reasoning LLM from Zero Data
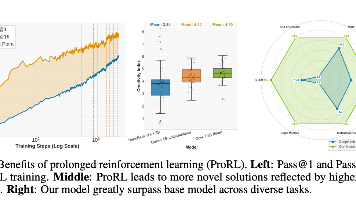
ProRL:延长强化学习训练,扩展大语言模型推理边界——NeurIPS 2025论文解读
ProRL: Prolonged Reinforcement Learning ExpandsReasoning Boundaries in Large Language Models