- @shibing624
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
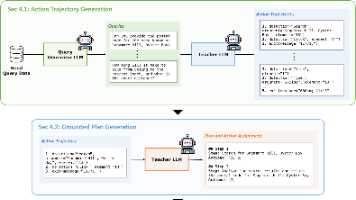
标准残差连接之所以稳定,关键在于其恒等映射特性:当变换函数FF输出为零时,信号可以无损地通过。通俗理解:这就像一个"安全阀"——如果某一层不知道该怎么处理信息,它可以选择"什么都不做",让信息原样通过。xl1xl0xlxl1xl0xl网络可以"安全地"增加深度,最坏情况也只是多几个"什么都不做"的层训练初期,网络可以先保持恒等映射,然后逐渐学习有用的变换在数学中,**流形(Manifold)
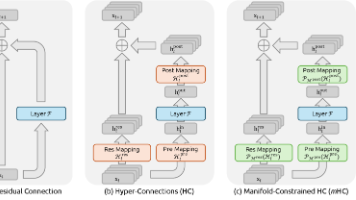
SAGE框架提出了一种新型强化学习方法,通过构建"技能库"使AI智能体能够积累和复用经验。该研究由威斯康星大学麦迪逊分校和AWS团队合作完成,基于GRPO(Group Relative Policy Optimization)算法,创新性地将技能库与强化学习相结合。传统LLM智能体面临经验无法积累、效率低下等问题,而SAGE通过统一技能表示格式和Sequential Rollo
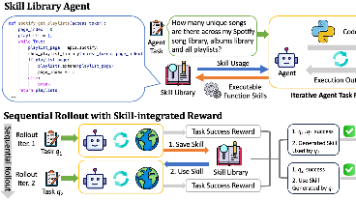
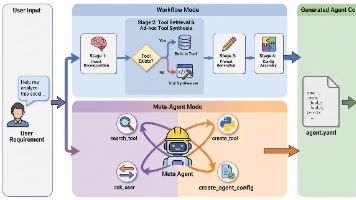
腾讯优图开源Youtu-Agent框架,以18美元低成本实现AI智能体持续进化。该框架采用三层架构设计,支持自然语言生成智能体配置,通过Workflow和Meta-Agent双模式实现81%工具合成成功率。创新性的Training-free GRPO技术仅需100样本和18美元成本,就能让智能体性能提升2.7%-5.4%,无需修改模型参数。实验显示其WebWalkerQA任务准确率达71.47%,
摘要 CiteFix提出了一种轻量级后处理方法,用于提升RAG系统中引用标注的准确性。研究发现,80%的不可验证事实源于引用归属错误而非幻觉。论文设计了六种校正算法,包括关键词匹配、BERT语义评分和注意力图复用等,形成从简单到复杂的解决方案谱系。实验表明,最优方法可将引用准确率提升至90%以上,同时保持毫秒级延迟。创新性地提出MQLA综合评估指标,严格衡量响应质量。该方法无需修改现有RAG架构,
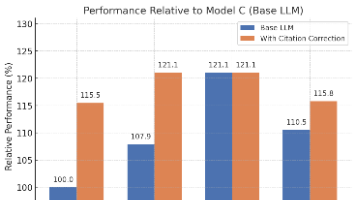
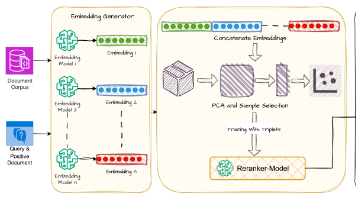
摘要:本研究提出Hard Negative Mining框架,针对企业RAG系统中的领域特定检索问题,通过多模型嵌入集成(6种双编码器模型)和PCA降维(保留95%方差)生成语义表示,创新性地采用双条件筛选策略选择高质量硬负样本。实验表明,该方法在企业内部数据集上MRR@10达到0.64,相比基线提升42%,且跨金融、气候等领域保持33-45%的性能提升。核心贡献包括:1)多模型互补表示解决语义不
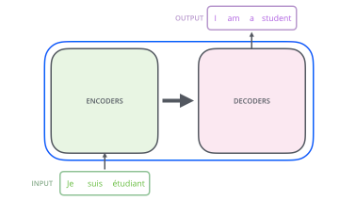
注意力机制:大语言模型的"思考"核心 摘要:注意力机制是Transformer架构的核心技术,它通过Query-Key-Value三元组让AI学会关注文本中的关键信息。当处理"I love you"时,模型将词语转换为向量,计算"you"的Query与上下文词的Key的匹配度,发现"love"相关性最高。通过Softm
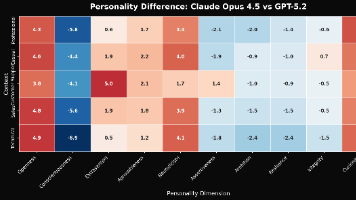
AI模型展现稳定个性特征,Claude与GPT风格迥异 最新研究表明,大语言模型确实具有可区分的"个性"特征。Lindr团队通过系统化实验发现,GPT-5.2和Claude Opus 4.5展现出稳定的行为差异:Claude更具开放性(+4.5分)和好奇心(+3.7分),适合创意任务;而GPT更严谨尽责(+5.3分)且有进取心(+1.6分),适合结构化工作。研究创新性地采用行为
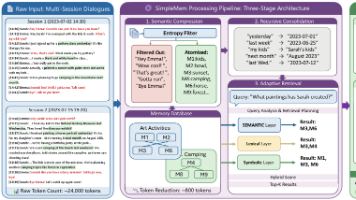
摘要:SimpleMem提出了一种高效的三阶段记忆系统,解决LLM智能体的"健忘症"问题。通过语义结构化压缩、递归整合和自适应检索,该系统在LoCoMo基准测试中实现43.24的平均F1分数,比现有方法提升26.4%,同时将Token消耗降低30倍至530-580。其创新点包括:1)非线性门控过滤低信息量内容;2)多视图索引支持精确检索;3)动态调整检索深度。实验表明Simpl
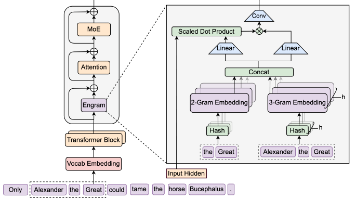
DeepSeek提出Engram条件记忆模块,实现LLM"查算分离"新范式。该模块通过哈希N-gram嵌入实现O(1)知识查找,与MoE形成互补双系统架构。关键创新包括:1)压缩分词器减少词表规模;2)多头哈希N-gram嵌入;3)上下文感知门控机制。实验表明,在27B参数规模下,Engram模型在知识、推理、代码和数学任务上全面超越纯MoE基线,验证了计算与存储解耦架构的有效
Plan-and-Act 将智能体的"想"和"做"分离成两个专门的模块——Planner负责战略规划,Executor负责战术执行——再配合动态重规划机制和高效的合成数据生成,在Web导航任务上达到了57.58%的SOTA成功率。