- @scgaliguodong123_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文将介绍 Milvus 系统中数据写入、索引构建、数据查询的具体处理流程,同时,还会介绍Milvus支持的索引类型;另外,还将讲述如何定义字段和集合Schema。数据与索引的处理流程数据写入用户可以为每个 collection 指定 shard 数量,每个 shard 对应一个虚拟通道 (vchannel)。如下图所示,在日志代理( log broker)内,每个 vchannel 被分配了一个
将 DevOps 方法应用于机器学习 (MLOps) 和数据管理 (DataOps) 越来越普遍。对于一个完善的 MLOps 平台来说,需要囊括资源编排(为模型训练提供服务器)、模型测试(验证模型推理)、模型部署到生产,以及模型监控和反馈等机器学习生命周期各个环节。 DVC 可以管理数据/模型和重现 ML 流水线,而 CML 可以协助编排、测试以及监控。ML 的 CI/CD(持续集成和持续交付)的
大数据面试指南(含答案)_v1包含Hadoop、Hive、Spark、Hbase、Java、Spring、Redis、Kafka等内容。下载链接:http://download.csdn.net/detail/scgaliguodong123_/9841862
本文将介绍 Milvus 系统中数据写入、索引构建、数据查询的具体处理流程,同时,还会介绍Milvus支持的索引类型;另外,还将讲述如何定义字段和集合Schema。数据与索引的处理流程数据写入用户可以为每个 collection 指定 shard 数量,每个 shard 对应一个虚拟通道 (vchannel)。如下图所示,在日志代理( log broker)内,每个 vchannel 被分配了一个
什么人工智能和人工智能系统人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。1956年由约翰.麦卡锡首次提出,当时的定义为“制造智能机器的科学与工程”。人工智能的目的就是让机器能够像人一样思考,让机器拥有智能。人工智能是计算机科学的一个分支。时至今日,人工智能已经扩展为一门交叉学科。人工智能系统是集成了人工智能技术的系统,做到了信息智能处理,提高了企业
本文简要介绍了两种比较常用的大模型量化方法 GPTQ、LLM.int8();LLM.int8() 属于 round-to-nearest (RTN) 量化:舍入到最近的定点数。而 GPT-Q 则是把量化问题视作优化问题,逐层寻找最优的量化权重。目前,这两种量化方法也集成到了Transformers库中,大家可以非常方便的使用。
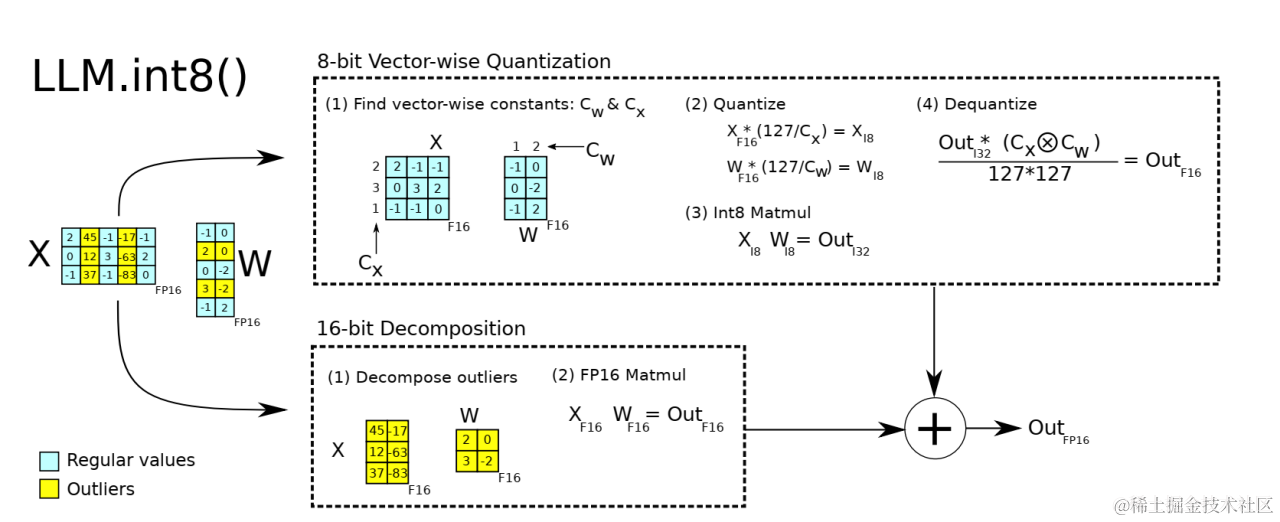
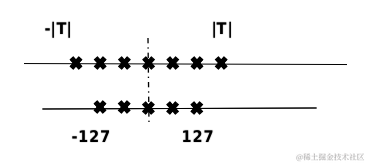
可以根据实际业务需求将原模型量化成不同比特数的模型,一般深度神经网络的模型用单精度浮点数表示,如果能用有符号整数来近似原模型的参数,那么被量化的权重参数存储大小就可以降到原先的四分之一,用来量化的比特数越少,量化后的模型压缩率越高。)发现对于LLM的性能,权重并不是同等重要的,通过保留1%的显著权重可以大大减少量化误差。因此,引入了一种新的策略,涉及通道级的平移和缩放操作,以纠正异常的不对称呈现,
KV Cache 是大模型推理性能优化的一个常用技术,该技术可以在不影响任何计算精度的前提下,通过空间换时间的思想,提高推理性能。本文简要分析了 KV Cache 原理、源码以及计算量和显存占用,这是一种典型的通过空间换时间(计算)的技术,虽然并不复杂,但是现在基本上是仅解码器Transformer架构生成大语言模型必备优化技术。图解大模型推理优化:KV Cache大模型推理百倍加速之KV cac
将 DevOps 方法应用于机器学习 (MLOps) 和数据管理 (DataOps) 越来越普遍。对于一个完善的 MLOps 平台来说,需要囊括资源编排(为模型训练提供服务器)、模型测试(验证模型推理)、模型部署到生产,以及模型监控和反馈等机器学习生命周期各个环节。 DVC 可以管理数据/模型和重现 ML 流水线,而 CML 可以协助编排、测试以及监控。ML 的 CI/CD(持续集成和持续交付)的
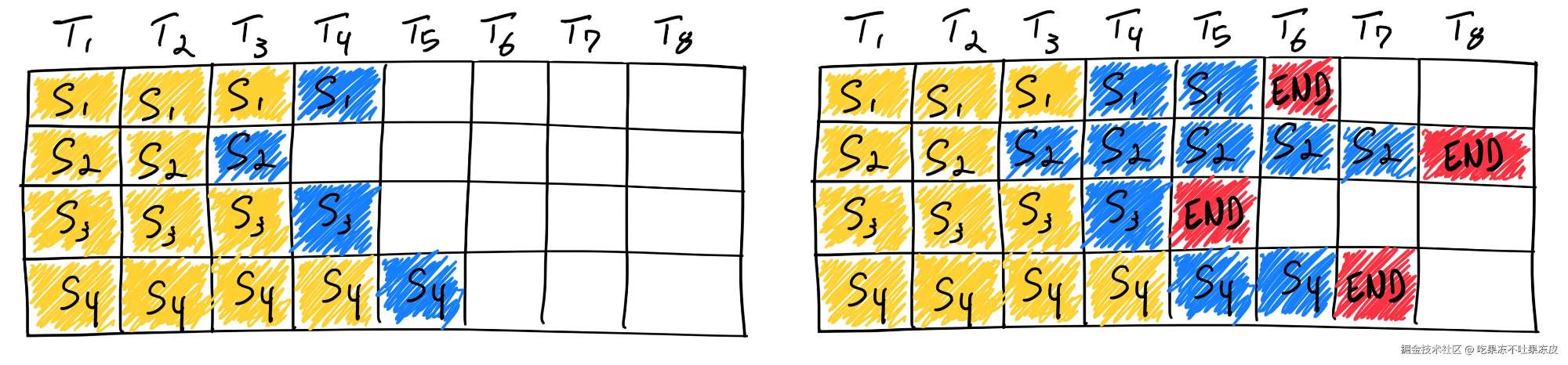
本文先介绍了不同批处理基本概念区别,然后,讲述了 LLM 推理框架中提升吞吐性能最重要的技术 Continuous batching。同时,分析了其在不同框架中的应用实现。LLM 推理加速方式汇总连续批处理借着triton inference server聊一下各种batching方法TurboMind 框架(TurboMind)LMDeploy 大模型量化部署实践从continuous batc