




- @qq_66878808
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
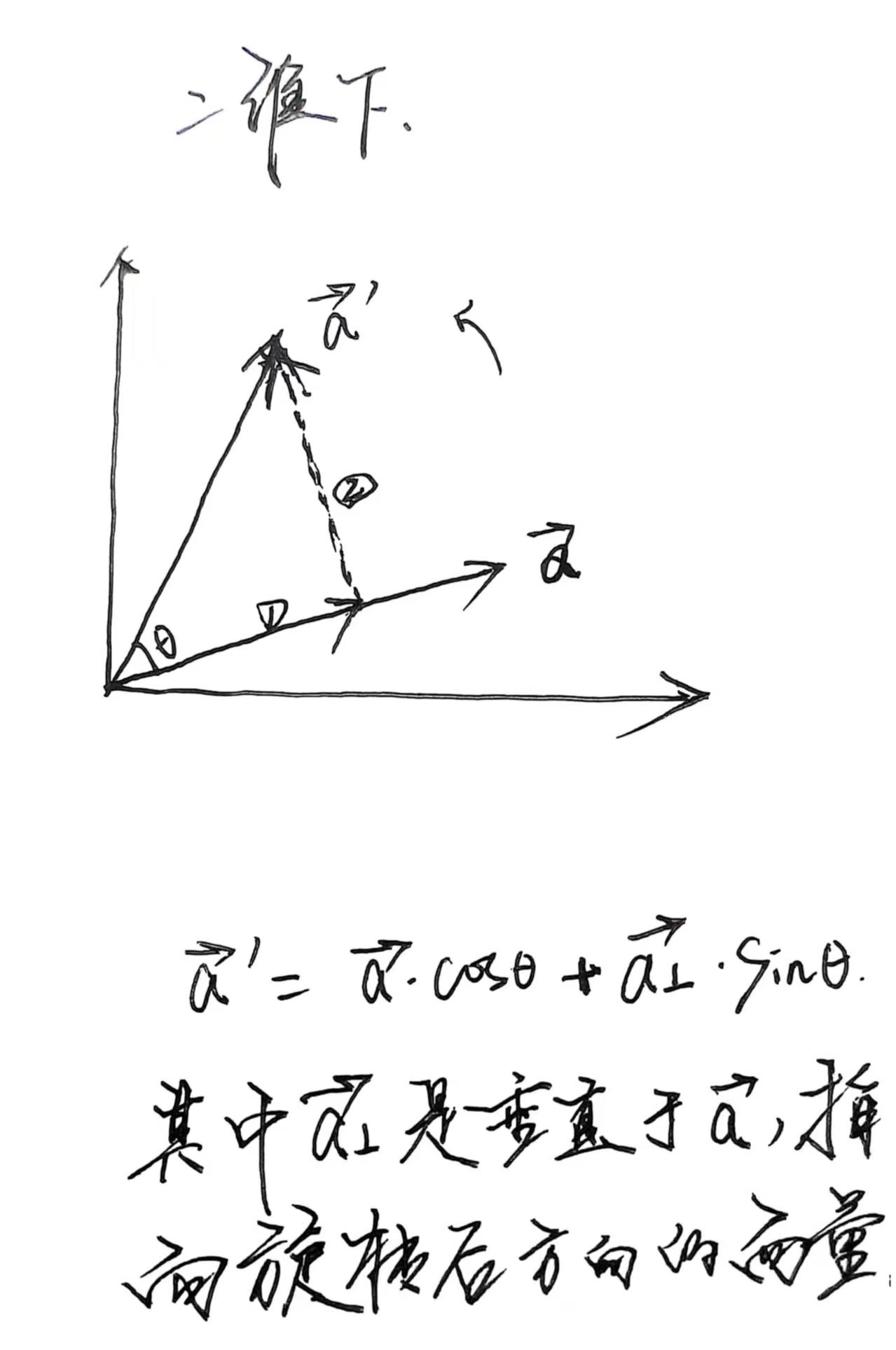
RcosθI1−cosθv⃗v⃗Tsinθv⃗×RcosθI1−cosθvvTsinθv×这就是从向量形式 → 矩阵形式的全过程推导。
所以我们要“反过来推”,从数据出发,倒推出这个参数。这就是最大似然的直觉: “哪个参数让我们实际观测到的数据。我们在每个类别内部进行建模的时候,类别标签已经是已知的固定量。假设我们要预测某人是否患病(1 or 0),你用逻辑回归来建模,参数是。所以 MLE 可以被看作一种“没有先验信息时的贝叶斯估计”。这就是贝叶斯方法“把模型参数的不确定性也考虑进来”的精髓。我们应该考虑所有可能的参数值,不要只依
前言:25年考察了三角形面积权重计算,没有在ppt中找到该知识,直接被暴击。
事件越不可预测(概率越低),其发生时提供的信息量应越大。均匀分布时熵最大(不确定性最高),确定分布时熵最小(零)。在某些情况下,我们不仅关心分类是否正确,还关心错误的代价。为此,我们引入损失函数。如果苹果的表面通常是光滑的,而橘子的表面通常是粗糙的,则。,即在给定观测值 x 的情况下,尽可能做出正确的分类决策。,当我们观察到数据 x 时,我们希望选择最可能的类别。:在已知 B 发生的情况下,事件
ID3 需要评估每个属性的信息增益。基尼指数衡量数据集的不纯度GiniS1−∑j1kPj2GiniS1−j1∑kPj2PjP_jPj是类别jjj在数据集SSS中的比例。基尼增益ΔGiniGiniS−∣SL∣∣S∣GiniSL∣SR∣∣S∣GiniSRΔGiniGiniS−∣S∣∣SL∣GiniSL∣S∣∣SR∣Gini。
事件越不可预测(概率越低),其发生时提供的信息量应越大。均匀分布时熵最大(不确定性最高),确定分布时熵最小(零)。在某些情况下,我们不仅关心分类是否正确,还关心错误的代价。为此,我们引入损失函数。如果苹果的表面通常是光滑的,而橘子的表面通常是粗糙的,则。,即在给定观测值 x 的情况下,尽可能做出正确的分类决策。,当我们观察到数据 x 时,我们希望选择最可能的类别。:在已知 B 发生的情况下,事件
所以我们要“反过来推”,从数据出发,倒推出这个参数。这就是最大似然的直觉: “哪个参数让我们实际观测到的数据。我们在每个类别内部进行建模的时候,类别标签已经是已知的固定量。假设我们要预测某人是否患病(1 or 0),你用逻辑回归来建模,参数是。所以 MLE 可以被看作一种“没有先验信息时的贝叶斯估计”。这就是贝叶斯方法“把模型参数的不确定性也考虑进来”的精髓。我们应该考虑所有可能的参数值,不要只依
通过误差反向传播来更新各层权重,从而逐步减少预测误差。输入信号流过网络,产生输出输出与期望结果对比,计算误差将误差从输出层反向传播至隐藏层基于误差更新权重,减少误差单次样本误差函数(instantaneous error):En12∑j∈Cdjn−yjn2En21j∈C∑djn−yjn2平均误差(用于 batch 模式):Eav1N∑n1NEnEavN1n1∑N。
山东大学软件学院人工智能导论期末复习

山东大学软件学院人工智能导论期末复习