




- @qq_62634342
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深度剖析了Hugging Face Transformers库中TokenClassification(命名实体识别)任务的模型推理输出与配置系统。文章从outputs.logits张量形状[1, 29, 32]切入,详解Batch维度、序列长度与类别数的对应关系,并阐明logits取Argmax及id2label映射的底层逻辑。同时,系统探究了AutoConfig.from_pretrain

本文系统讲解了Python进度条库`tqdm`从入门到精通的实战技巧。内容不仅涵盖基础安装、常规循环及Jupyter Notebook中的可视化用法,更深入解析了`desc`、`total`等核心参数的配置策略。文章重点剖析了训练日志中`it/s`与`s/it`的底层含义及转换逻辑,演示了如何通过日志数据反推Batch Size,帮助开发者实现从“会用工具”到“性能调优”的进阶,是提升代码可视化与

本文系统讲解了PyTorch中的梯度计算机制。主要内容包括:1)张量的基本概念,区分标量张量和向量张量的形状表示;2)PyTorch自动计算的是数学梯度而非负梯度,优化方向由优化器处理;3)线性函数的导数与全局变化率关系;4)上游梯度的概念及其在反向传播中的作用;5)动态计算图的构建原理和前向/反向传播过程;6)梯度计算的完整流程,通过具体示例展示链式法则的应用;7)损失函数的来源与反向传播条件;
在大模型(LLM)时代,归一化层的选择与底层精度的控制直接决定了训练的稳定性与效率。本文深入剖析了已成为工业标准的 RMSNorm(均方根归一化),从数学直觉出发,对比 LayerNorm 揭示其“去冗余”的设计哲学。不仅如此,文章还深度解读了 PyTorch 混合精度训练 中的“精度三角”—— FP32、FP16 与 BF16 的博弈。通过实战代码,我们将展示如何利用 torch.rsqrt 进

CIFAR-10是一个经典的图像分类数据集,包含60,000张32×32彩色图像,分为10个类别(如飞机、汽车、鸟类等)。数据集分为50,000张训练图像和10,000张测试图像,常用于机器学习模型的开发和评估。PyTorch提供了CIFAR10类,支持自动下载和图像预处理,通过transform参数可将PIL图像转换为模型所需的Tensor格式,并进行数据增强(如随机翻转、裁剪等)。该数据集因图

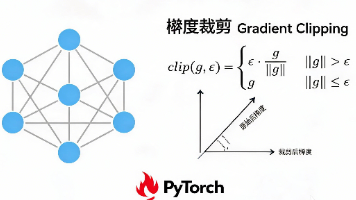
梯度裁剪是大模型训练中防止梯度爆炸、保障数值稳定性的核心技术。本文从零基础到工程实战,系统解析了梯度裁剪的数学原理与PyTorch落地细节。内容涵盖Clip by Norm的全局缩放机制与方向守恒证明、clip_grad_norm_ API参数深度拆解(含norm_type选型与foreach性能优化)、AMP混合精度下的正确调用时序,以及max_norm的动态监控与调优策略。文章还特别辨析了梯度
在深度学习模型的训练过程中,参数初始化往往被视为决定模型“生死”的第一步。不合理的初始化策略极易引发梯度消失、梯度爆炸或模型输出NaN等顽疾,导致模型无法收敛。本文立足于2026年深度学习工业界的最新实践标准,深入剖析PyTorch框架下Transformer等大模型的参数初始化核心机制。文章不仅系统梳理了Xavier、Kaiming等经典初始化方法的数学原理与适用场景,更重点解读了如何利用PyT

CIFAR-10是一个经典的图像分类数据集,包含60,000张32×32彩色图像,分为10个类别(如飞机、汽车、鸟类等)。数据集分为50,000张训练图像和10,000张测试图像,常用于机器学习模型的开发和评估。PyTorch提供了CIFAR10类,支持自动下载和图像预处理,通过transform参数可将PIL图像转换为模型所需的Tensor格式,并进行数据增强(如随机翻转、裁剪等)。该数据集因图
机器学习分类任务中,精确率、准确率和召回率是核心评估指标。准确率衡量整体预测正确率,适用于均衡数据;精确率关注预测正类的可靠性,强调减少误报;召回率评估查全能力,注重减少漏报。三者各有侧重,F1分数则综合了精确率和召回率。以癌症检测为例,即使准确率高,仍需关注召回率(避免漏诊)和精确率(减少误诊)。不同场景应选择合适的指标进行评估。

本文介绍了使用神经网络预测二手手机价格区间的分类问题。首先通过数据分析确定20个特征参数与4个价格区间(0-3)的关系,然后构建了一个包含批量归一化、ReLU激活和Dropout正则化的三层全连接网络模型。模型采用PyTorch实现,包含128和256个节点的两个隐藏层,最终输出4个类别的预测结果。文中详细展示了数据预处理、模型架构设计和参数初始化过程,并提供了模型结构可视化方法。该方案通过分类而
