




- @qq_62173470
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
由于有好几个参数min_child_weights,subsamples,consample_bytrees没有跑,没找出最优的值,所以最后的log_loss的值还是有些大的。:集成中只包含同种类型的“个体学习器”相应的学习算法称为“基学习算法”(base learning algorithm)(串行)基本思想:基分类器层层叠加,每一层在训练的时候对前一层基分类器分错的样本给予更高的权重。,训练得
决策树:是一种树形结构,其中每个内部节点表四一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点表示一种分类结果,本质是一颗由多个判断节点组成的树。,如在信息增益案例题中,我们计算时忽略了第一列即编号列,实际上信息增益会偏向选择第一列(类别有15种)、第三列(类别有3种)…ID3、C4.5、CART在特征选择的时候都是选择一个最优的特征来分类决策,但是不应该只由某一个特征进行决定,应该
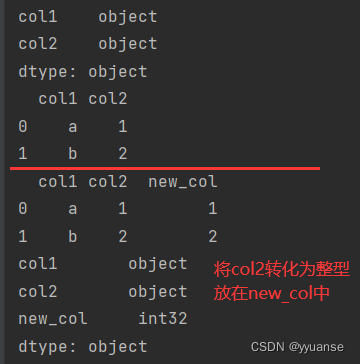
转化数据类型、处理重复数据、处理缺失数据。
缺点:会忽略文本的表达顺序,如我爱你和你爱我,表示都一样。是指在一个向量中,只有一个位置上的值是1,其他位置都是0.缺点:无法表现词与词之间的语义关系,当数据量大的时候,维数也会变得很大。:与Count Vectors类似,不过加入了相邻单词组合成新的单词,并且进行计数。stopwords.csv上网找一个中文禁用词表即可,我用的是这一篇博客提供的。适合完完全全的小白读,有其他语言经验的可以去看别
有些编译工具在绘图的时候不需要写plt.show()或者是print就可以显示绘图结果或者是显示打印结果,pycharm需要(matplotlib.pyplot)
由于有好几个参数min_child_weights,subsamples,consample_bytrees没有跑,没找出最优的值,所以最后的log_loss的值还是有些大的。:集成中只包含同种类型的“个体学习器”相应的学习算法称为“基学习算法”(base learning algorithm)(串行)基本思想:基分类器层层叠加,每一层在训练的时候对前一层基分类器分错的样本给予更高的权重。,训练得
由于有好几个参数min_child_weights,subsamples,consample_bytrees没有跑,没找出最优的值,所以最后的log_loss的值还是有些大的。:集成中只包含同种类型的“个体学习器”相应的学习算法称为“基学习算法”(base learning algorithm)(串行)基本思想:基分类器层层叠加,每一层在训练的时候对前一层基分类器分错的样本给予更高的权重。,训练得