
写文章




- @qq_60199131
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
视觉语言大模型模型介绍-CLIP学习
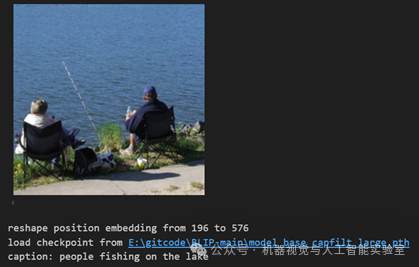
在这个场景中,配对的图像和文本对是正样本,因为它们描述的是相同的内容,这些正样本位于特征矩阵的对角线上。2、 2022年的BL1P, 之前的CLIP是一个图像理解模型,不能对图像进行一个文本描述生成,它是一个集图像生成和文本描述为一体的模型,并且,它考虑到从网络上采集(爬取)的数据存在大量噪声,(这个噪声指图片对应的标签、文本 错误、不匹配),BLIP模型采用了一种称为CapFilt ( Capt
视觉语言大模型模型介绍-CLIP学习
在这个场景中,配对的图像和文本对是正样本,因为它们描述的是相同的内容,这些正样本位于特征矩阵的对角线上。2、 2022年的BL1P, 之前的CLIP是一个图像理解模型,不能对图像进行一个文本描述生成,它是一个集图像生成和文本描述为一体的模型,并且,它考虑到从网络上采集(爬取)的数据存在大量噪声,(这个噪声指图片对应的标签、文本 错误、不匹配),BLIP模型采用了一种称为CapFilt ( Capt
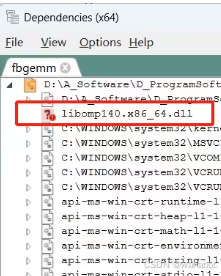
[WinError 126] 找不到指定的模块。 Error loading “D:\,,,\Anaconda\Lib\site-packages\torch\lib\fbgemm.dll“ or o
Error loading "D:\,,,\Anaconda\Lib\site-packages\torch\lib\fbgemm.dll" or one of its dependencies.下载完后,把文件中的“libomp140.x86_64.dll”复制到报错的文件夹下(D:\。\Anaconda\Lib\site-packages\torch\lib\),就解决了。主要原因就是缺失文件
YOLOv8-详细模块学习
YOLOv8细节,各个模块的发展、讲解和代码

到底了