




- @qq_55953518
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
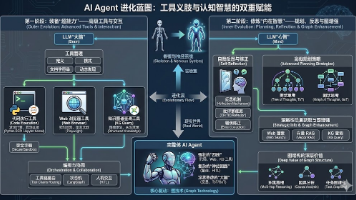
摘要: DeepSeek(深度求索)从2023年至今完成了从追赶者到AGI领跑者的蜕变,其发展分为五个阶段: V1阶段(2023-2024初):聚焦代码与数学能力,以DeepSeek Coder V1在开发者圈层引爆,击败千亿参数模型。 V2阶段(2024年中):通过MLA(多头潜在注意力)和MoE架构实现极致成本优势,发动“价格战”成为企业首选。 V3阶段(2024年底):采用FP8训练和MTP
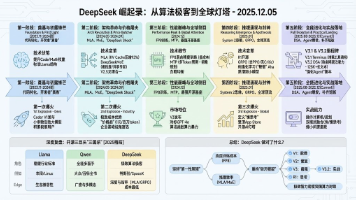
本文深入解析了AIAgent领域的两种主流执行逻辑:ReAct(推理与行动)和Plan-and-Execute(规划与执行)。ReAct采用"思考-行动-观察"的迭代循环,具有灵活性和适应性强的特点,适合处理动态环境;而Plan-and-Execute采用先规划后执行的线性流程,执行效率高但适应性较差。文章通过对比分析两者的优劣势,并以天气查询任务为例展示了不同执行逻辑的行为差
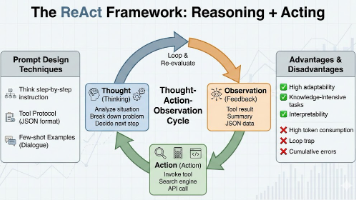
本文探讨了构建高级AIAgent的两大关键进化维度:通过集成工具链赋予"超能力",以及通过反思与规划策略提升认知智慧。在工具层面,重点分析了代码执行、Web浏览器和知识图谱三大"神器"的功能与协同机制,强调结构化定义和动态路由的重要性。在认知层面,提出自我反思机制和复杂规划策略(树状/图状思考),并阐释了知识图谱在推理优化中的核心价值。最终呈现了一个兼具强大
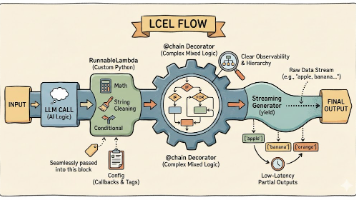
摘要:LangChain表达式语言(LCEL)是AI应用开发的重要工具,提供了10个核心特性解决生产级问题:1)数据流控制(RunnablePassthrough、RunnableParallel);2)运行时参数绑定;3)自定义逻辑嵌入;4)混合开发装饰器;5)流式处理支持;6)容错回退机制;7)记忆管理;8)动态路由决策;9)可视化调试工具。LCEL实现了从脚本开发到声明式编排的转变,通过标准
LeetCode283题要求将数组中的0移到末尾,保持非零元素顺序且原地操作。本文提供两种Java解法:方法一采用"覆盖后填充"策略,先移动非零元素再补零,时间复杂度O(n);方法二使用双指针交换技术,通过一次遍历完成操作。分析比较了两种方法在操作次数、代码可读性和适用场景上的差异,推荐Java开发者优先使用方法一,因其逻辑清晰且利用了高效的Arrays.fill方法。两种解法
本文深入解析LeetCode第11题"盛最多水的容器",通过分析题目核心公式和暴力解法的局限性,重点介绍了双指针优化算法。文章详细阐述了"谁短动谁"的移动策略原理,并给出严谨数学证明,说明该策略能确保最优解。最后提供了Java代码实现和复杂度分析,指出这道题是贪心算法与双指针结合的经典案例,关键在于理解如何通过移动短板指针来高效缩小搜索空间。
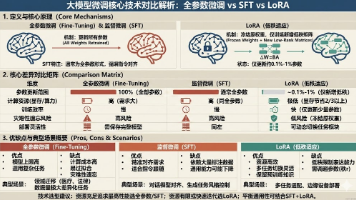
本文对比分析了三种大模型微调技术:全参数微调(更新所有参数)、监督微调(SFT,侧重指令对齐)和LoRA(低秩适应,仅训练少量参数)。全参数微调适合领域重构但成本高,SFT擅长指令对齐,LoRA则资源友好但表达能力受限。建议资源充足时采用全参数微调或SFT,资源有限时选择LoRA,或结合SFT与LoRA实现通用性与专业性的平衡。技术选择应基于具体任务需求、数据特点和算力条件。
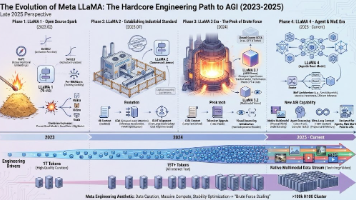
LLaMA 1到3的飞跃,主要不是靠改模型结构(一直都是Decoder-only Transformer),而是靠更高质量的数据清洗(Data Curation)和更暴力的Scaling。Meta证明了:即便模型参数不大(如7B, 13B),只要用足够多、足够高质量的数据(1T tokens)去“过饱和”训练,性能可以吊打比它大得多的模型(如GPT-3 175B)。:模仿了OpenAI o1系列的
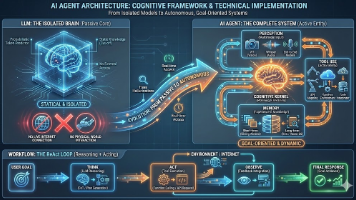
LLM(如 GPT-4, Llama 3, Qwen)本质上是一个概率预测机器。输入一段文本,根据海量训练数据,概率性地预测下一个 Token 是什么。它是静态的、被动的。它没有身体,无法联网(除非外挂),无法直接操作数据库,且它的知识截止于训练结束的那一刻。它就像一个被锁在密室里、读过人类所有书籍的“天才”,但他瘫痪在床,且与外界完全隔绝。Agent 指的是一个能够感知环境、进行推理决策,并采取
本文深入探讨思维链(CoT)从用户技巧到模型本能的演变过程。在用户层面,CoT通过"一步步思考"的提示词引导AI展示推理过程,分为零样本和少样本两种应用方式。在模型层面,以DeepSeek-R1为例,详细解析了CoT内化的四个阶段:冷启动SFT建立格式、强化学习逼出推理能力、泛化训练扩展应用场景、RLHF对齐人类价值观。文章指出,新一代模型已内化CoT能力,自动进行深度思考,而
