




- @qq_55653355
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
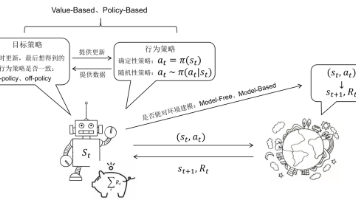
本文是一篇强化学习笔记,主要涵盖以下内容:1) 数学基础部分介绍了马尔可夫性质、概率质量函数、期望值和方差等概念;2) 强化学习基础概念部分详细讲解了Agent、action、Environment、reward和State等核心要素;3) 值函数方法部分深入分析了状态价值函数和动作价值函数,包括它们的定义、关系以及贝尔曼方程的推导过程。文章还提供了多个优质学习资源的链接,适合有一定基础的读者梳理
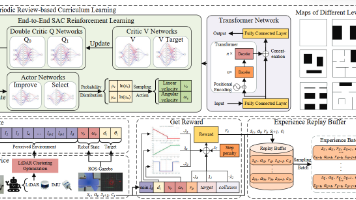
本文提出CTSAC算法,将Transformer的时序建模能力融入SAC框架,解决目标导向的机器人探索任务中存在的局部最优和训练不稳定问题。方法创新包括:1) 设计基于前进方向的LiDAR非均匀分段方法,优化环境感知;2) 构建包含7项奖惩的复合奖励函数,引导有效探索;3) 用Transformer网络替换SAC的全连接层,捕获状态序列的时间依赖关系。实验表明,该方法能有效利用历史状态信息,避免局
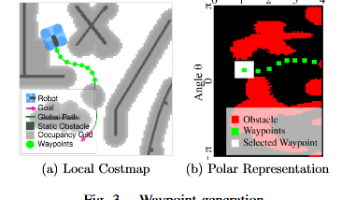
本文提出了一种混合经典/强化学习(RL)的局部路径规划器,结合DWA算法和SAC强化学习的优势。创新点包括:1)采用极坐标代价地图提升避障直观性,增强仿真到实机的迁移能力;2)基于启发式规则(如障碍物距离阈值)实现规划器动态切换,无需额外训练。系统通过虚拟走廊检测路径净空状态,并采用滤波机制避免传感器噪声导致的频繁切换。实验表明,混合方法在保持DWA高效性的同时,通过SAC解决了DWA在复杂障碍下
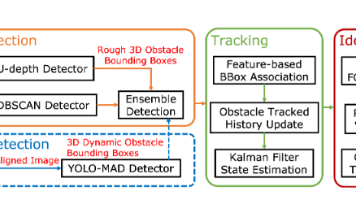
本文提出一种基于RGB-D相机的轻量级三维动态障碍物检测与跟踪方法(DODT),专为资源受限的机器人设计。系统采用三种计算效率高的非学习型检测器(U-depth、DBSCAN、YOLO-MAD)进行集成检测,通过特征匹配和IOU验证实现鲁棒识别,并引入可选学习模块增强性能。跟踪模块提出基于特征向量的匹配方法和恒加速度卡尔曼滤波,通过融合位置、尺寸和点云统计特征,有效解决目标混淆问题,在保证实时性的
本文提出了一种混合经典/强化学习(RL)的局部路径规划器,结合DWA算法和SAC强化学习的优势。创新点包括:1)采用极坐标代价地图提升避障直观性,增强仿真到实机的迁移能力;2)基于启发式规则(如障碍物距离阈值)实现规划器动态切换,无需额外训练。系统通过虚拟走廊检测路径净空状态,并采用滤波机制避免传感器噪声导致的频繁切换。实验表明,混合方法在保持DWA高效性的同时,通过SAC解决了DWA在复杂障碍下
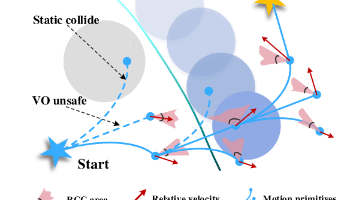
本文综述了动态环境中机器人运动规划的常见方法。主要分为三类:反应式方法(如DWA、APF)响应快但短视保守;基于速度障碍(VO)的方法能有效避障但同样存在短视问题;基于MPC的方法能生成平滑轨迹但计算量大。表格对比显示,反应式方法效率高但易抖动,VO方法避障效果好但保守,MPC方法轨迹平滑但可能陷入局部最优。总体而言,现有方法在动态环境中面临短视、保守或计算复杂等挑战,需要平衡实时性与轨迹质量。
本文提出一种基于RGB-D相机的轻量级三维动态障碍物检测与跟踪方法(DODT),专为资源受限的机器人设计。系统采用三种计算效率高的非学习型检测器(U-depth、DBSCAN、YOLO-MAD)进行集成检测,通过特征匹配和IOU验证实现鲁棒识别,并引入可选学习模块增强性能。跟踪模块提出基于特征向量的匹配方法和恒加速度卡尔曼滤波,通过融合位置、尺寸和点云统计特征,有效解决目标混淆问题,在保证实时性的
本文是一篇强化学习笔记,主要涵盖以下内容:1) 数学基础部分介绍了马尔可夫性质、概率质量函数、期望值和方差等概念;2) 强化学习基础概念部分详细讲解了Agent、action、Environment、reward和State等核心要素;3) 值函数方法部分深入分析了状态价值函数和动作价值函数,包括它们的定义、关系以及贝尔曼方程的推导过程。文章还提供了多个优质学习资源的链接,适合有一定基础的读者梳理