




- @qq_54827663
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OCR字符识别需要用到OCR库,我首先尝试过使用Tesseract来进行OCR识别,但是效果不尽人意,之后尝试使用百度飞桨的OCR库paddleocr进行识别,效果符合预期。由于车牌颜色多种多样,无法使用颜色阈值的方法来提取车牌,因此考虑使用形态学操作的方法来提取车牌。预处理的工作,就是使用传统图像处理技术,从图像中找到车牌的位置并截取出来以供OCR使用。图像顶帽(或图像礼帽)运算是原始图像减去图

安装dlib-19.24时出现报错subprocess.CalledProcessError: Command '['cmake', '--build', '.', '--config', 'Release', '--', '/m']' returned non-zero exit status 1
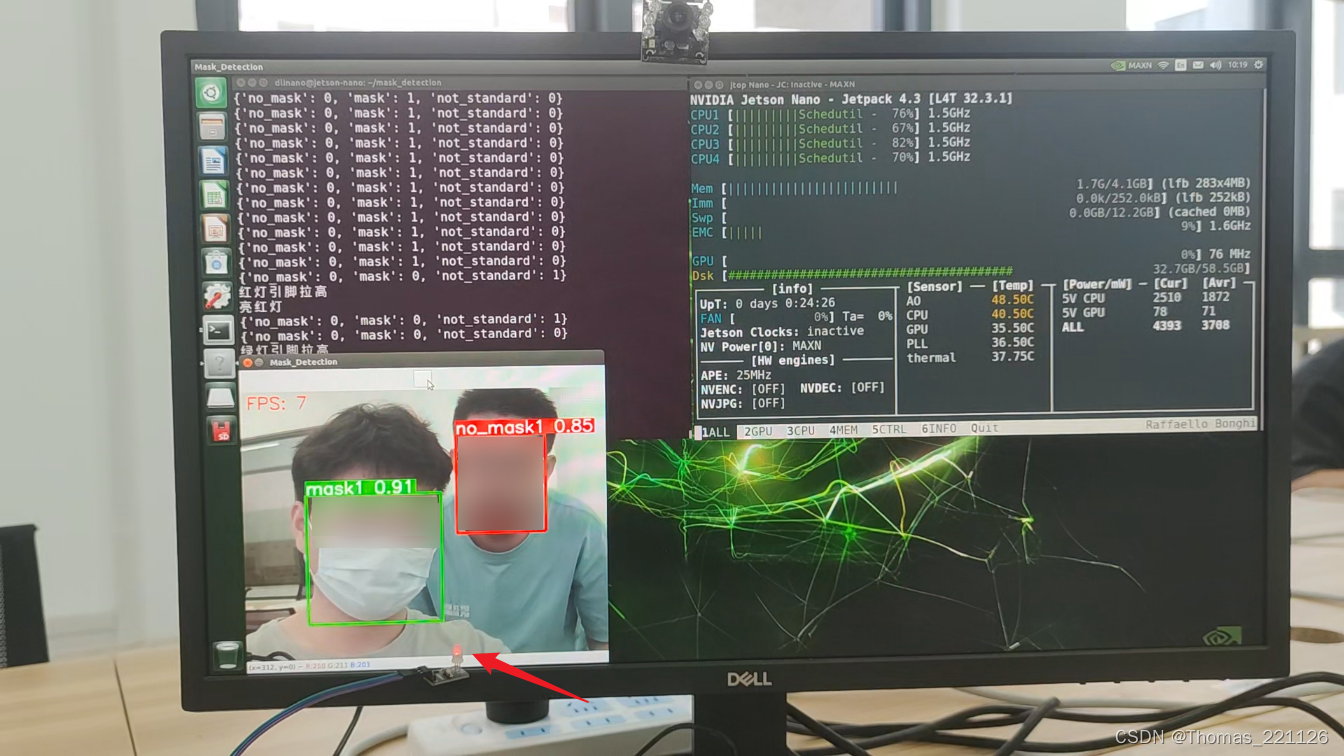
使用YOLOv5训练口罩识别模型,共分为三类:未佩戴口罩、正确佩戴口罩、未正确佩戴口罩。并将pt模型部署于Jetson Nano边缘计算平台上,实现口罩识别、点亮LED和语音播报功能,识别速度为8-13帧/秒。
运行打包的exe时出现闪退,查看报错信息:No module named 'openpyxl.cell._writer',使用PyInstaller的"hooks"机制解决
OCR字符识别需要用到OCR库,我首先尝试过使用Tesseract来进行OCR识别,但是效果不尽人意,之后尝试使用百度飞桨的OCR库paddleocr进行识别,效果符合预期。由于车牌颜色多种多样,无法使用颜色阈值的方法来提取车牌,因此考虑使用形态学操作的方法来提取车牌。预处理的工作,就是使用传统图像处理技术,从图像中找到车牌的位置并截取出来以供OCR使用。图像顶帽(或图像礼帽)运算是原始图像减去图
本文简要介绍了如何使用Python+OpenCV+Tesseract实现OCR字符识别
