




- @qq_53879585
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
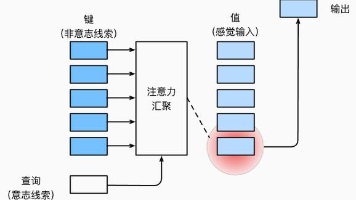
上节课讲的使用高斯核来建立query和keys之间的关系函数,现在将query和keys放入注意力评分函数(Attention scoring function)中,然后将该函数的输出结果放入softmax函数中。这样我们可以得到注意力权重,最后注意力权重的值的加权和作为输出。
其中,比较重要的层分别是:Conv2d是卷积层,输入到输出的过程中使用了适当的填充(padding),使得输出的高度和宽度与输入相同,且通道数增加6;Flatten将多维张量展平为一维向量,输入形状为 (1,16,5,5),展平后为 (1,16*5*5) = (1,400);LeNet网络的输入层通常为通道数为1的灰度图像,其大小为32×32,输出层是一个由10个神经元组成的softmax高斯连接

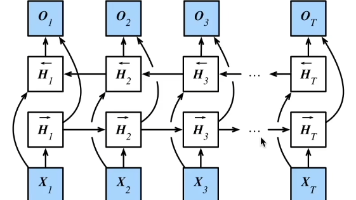
本文对《动手学深度学习v2》课程关于循环神经网络的所有部分做一个总结。目录一、循环神经网络RNN1. 简介2. 循环神经网络核心公式3.困惑度(perplexity)4. 梯度剪裁(Gradient Clipping)二、实现RNN网络1. 从零开始实现2. 简洁实现三、GRU门控循环单元1. 简介2. 代码实现四、LSTM长短期记忆网络1. 简介2. LSTM对比GRU3. 代码实现五、深层循环
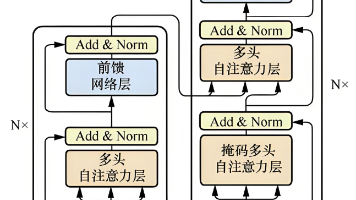
本文通过学习李沐基于pytorch的深度学习课程第68课Transformer,对该模型的原理做出总结并展示代码,作为本人学习笔记。
首先,定义AlexNet模型,在这里使用的仍然是是Fashion-MNIST数据集,因为训练ImageNet需要几个小时甚至几天,这里仅快速演示一下AlexNet网络,所以输入的是单通道(灰度)图像,最后输出层的类别数为10。第二卷积层(Conv2)的卷积核大小为5x5,数量256,步长为1,填充为2,输出尺寸为27x27x256,因使用填充(padding)所以特征图尺寸不变,同时增加通道数以提
首先,定义AlexNet模型,在这里使用的仍然是是Fashion-MNIST数据集,因为训练ImageNet需要几个小时甚至几天,这里仅快速演示一下AlexNet网络,所以输入的是单通道(灰度)图像,最后输出层的类别数为10。第二卷积层(Conv2)的卷积核大小为5x5,数量256,步长为1,填充为2,输出尺寸为27x27x256,因使用填充(padding)所以特征图尺寸不变,同时增加通道数以提
本文通过学习李沐基于pytorch的深度学习课程第68课Transformer,对该模型的原理做出总结并展示代码,作为本人学习笔记。
首先,定义AlexNet模型,在这里使用的仍然是是Fashion-MNIST数据集,因为训练ImageNet需要几个小时甚至几天,这里仅快速演示一下AlexNet网络,所以输入的是单通道(灰度)图像,最后输出层的类别数为10。第二卷积层(Conv2)的卷积核大小为5x5,数量256,步长为1,填充为2,输出尺寸为27x27x256,因使用填充(padding)所以特征图尺寸不变,同时增加通道数以提
这一整段是训练模型的核心代码,train函数需要定义(训练的神经网络模型net,训练集的特征数据和标签数据,测试集的特征数据和标签数据,训练的轮数num_epochs,控制优化器更新参数的步长的学习率learning_rate,用于防止过拟合的正则化系数weight_decay,每次迭代使用的批量大小batch_size)这段代码定义了get_k_fold_data 的函数是为了实现 K折交叉验证

李老师在举识别“猫”的例子,说明每个卷积核可以学习提取输入数据中的某种特定特征,最底层卷积识别一些边缘的纹理得到多个不同的输出通道,这些输出再继续作为下一个层输入,分别去识别猫胡须的纹理、耳朵的纹理等等,将这些纹理组合起来,再往下一层卷积走,某个通道识别猫头,某个通道识别猫眼,那最后一层输出就是所有东西组合起来识别出一只猫。不同的是,池化层没有可学习的参数(比如卷积核),在每个输入通道应用池化层以