




- @qq_52144300
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
下图为Omni的应用场景概述图,主要思想就是让多模态数据(文字、图片、视频、音频)输入模型,然后通过文字大模型(Thinker)进行理解,然后配合语音大模型(Talker)进行语音输出。
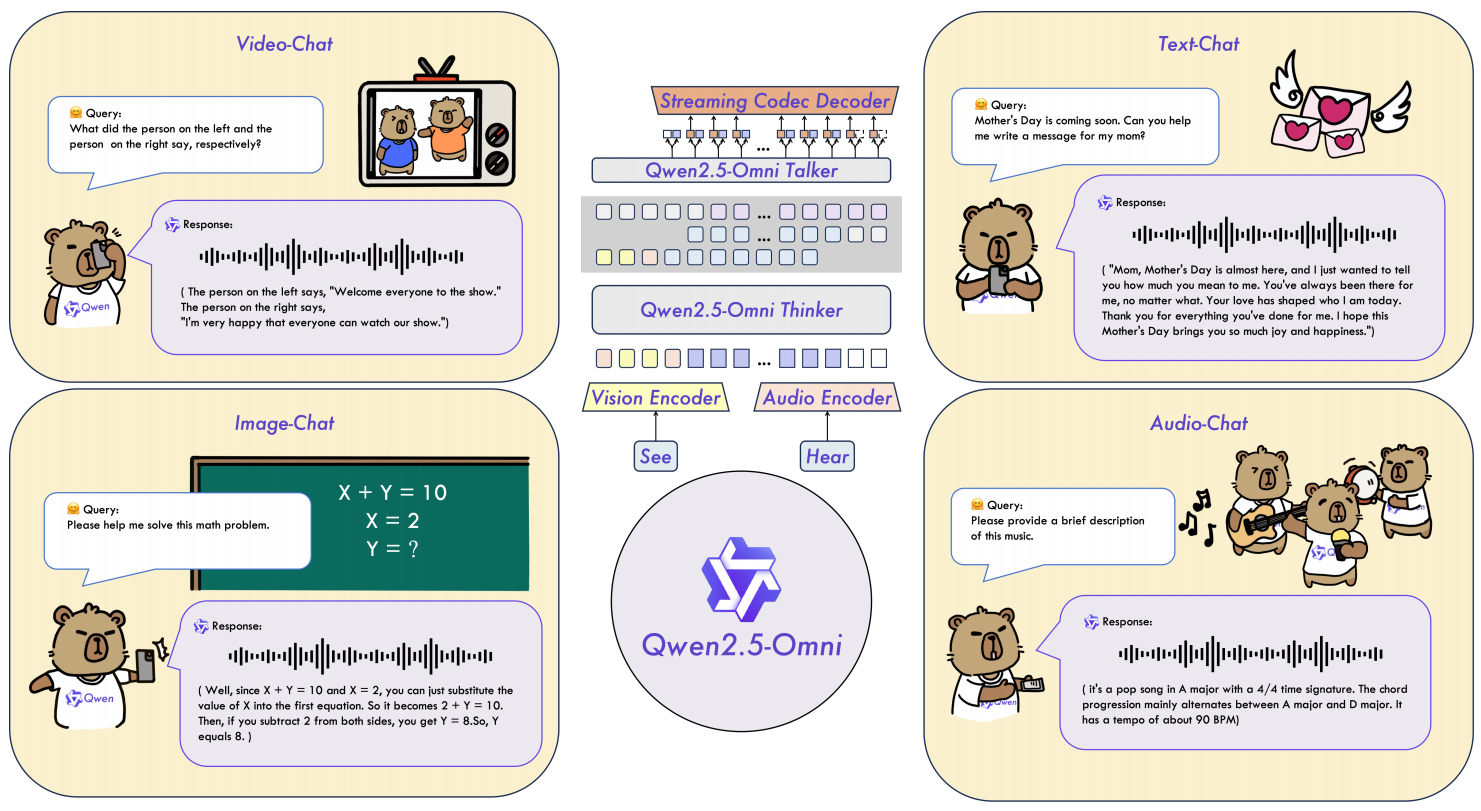
下图为Omni的应用场景概述图,主要思想就是让多模态数据(文字、图片、视频、音频)输入模型,然后通过文字大模型(Thinker)进行理解,然后配合语音大模型(Talker)进行语音输出。
(这里只能说是vLLM牛,对显存的拿捏十分精准)比如在上面的配置下,Qwen/Qwen2.5-7B-Instruct模型有两个实例,并且两个实例的权重优先级(devices中的weight参数)分别为1和2,那么最终请求会按照1:2的比例分配到两个实例上。如下所示,首先需要确保的是每一个模型实例的engine_args参数的model参数,这是模型权重的位置,不要填错,你可以从huggingfac

下图为Omni的应用场景概述图,主要思想就是让多模态数据(文字、图片、视频、音频)输入模型,然后通过文字大模型(Thinker)进行理解,然后配合语音大模型(Talker)进行语音输出。
(这里只能说是vLLM牛,对显存的拿捏十分精准)比如在上面的配置下,Qwen/Qwen2.5-7B-Instruct模型有两个实例,并且两个实例的权重优先级(devices中的weight参数)分别为1和2,那么最终请求会按照1:2的比例分配到两个实例上。如下所示,首先需要确保的是每一个模型实例的engine_args参数的model参数,这是模型权重的位置,不要填错,你可以从huggingfac
下图为Omni的应用场景概述图,主要思想就是让多模态数据(文字、图片、视频、音频)输入模型,然后通过文字大模型(Thinker)进行理解,然后配合语音大模型(Talker)进行语音输出。
(这里只能说是vLLM牛,对显存的拿捏十分精准)比如在上面的配置下,Qwen/Qwen2.5-7B-Instruct模型有两个实例,并且两个实例的权重优先级(devices中的weight参数)分别为1和2,那么最终请求会按照1:2的比例分配到两个实例上。如下所示,首先需要确保的是每一个模型实例的engine_args参数的model参数,这是模型权重的位置,不要填错,你可以从huggingfac
【代码】vue3开源组件vue-activity-calendar,类似GitHub贡献图的高自由度组件。
