- @qq_51659249
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
生物医学成像是科学发现的驱动力,也是医疗保健的核心组成部分,并受到深度学习领域的刺激.虽然语义分割算法在许多应用中支持图像分析和量化,但相应的专业解决方案的设计并非易事,并且高度依赖于数据集属性和硬件条件。我们开发了 nnU-Net,这是一种基于深度学习的分割方法,可以自动配置自身,包括任何新任务的预处理、网络架构、训练和后处理。在此过程中的关键设计选择被建模为一组固定参数、相互依赖的规则和经验决
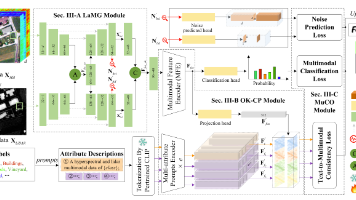
—世界模型能够显著增强层次化理解能力,从而提升数据整合能力和学习效率。为探索世界模型在遥感(remote sensing,RS)领域中的应用潜力,本文提出了一种面向多模态数据融合的标签高效遥感世界模型 FusDreamer。FusDreamer 将世界模型作为统一的表征容器,用于抽象不同类型数据之间共有的高层知识,并促进高光谱影像(hyperspectral image,HSI)、激光雷达(lig
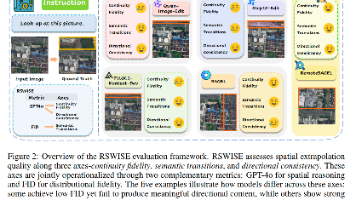
世界模型通过预测和推理直接观测之外的世界状态,在人工智能领域展现出巨大潜力。然而,现有方法主要在合成环境或受限场景设置中进行评估,限制了其在具有广域空间覆盖和复杂语义的真实世界场景中的验证。与此同时,灾害响应和城市规划等遥感应用迫切需要具备空间推理能力的方法。本文通过提出首个面向遥感领域的世界建模框架,弥合了上述差距。我们将遥感世界建模形式化为方向条件下的空间外推任务,即模型在给定中心观测图像块和
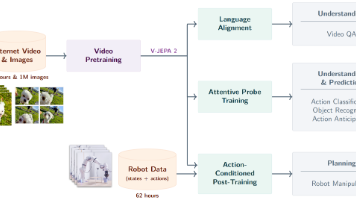
现代人工智能面临的一项重大挑战,是如何主要通过观察来学习理解世界并学会行动(LeCun,2022)。本文探索了一种自监督方法,将互联网规模的视频数据与少量交互数据(机器人轨迹)相结合,以开发能够在物理世界中进行理解、预测和规划的模型。我们首先在一个包含超过100万小时互联网视频的视频与图像数据集上,预训练了一个不依赖动作信息的联合嵌入预测架构 V-JEPA 2。V-JEPA 2 在运动理解任务上表
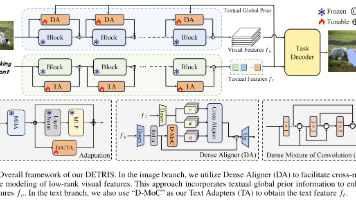
但它们提出的模块(如 Bridger,Xu et al., 2023;一些开创性工作(如 ETRIS 和 BarleRIa,Wang et al., 2023)尝试以参数高效的方式微调 CLIP(Radford et al., 2021)以用于指代表达图像分割,但仍面临若干局限:(i)这些方法主要依赖于在骨干网络早期阶段进行多模态特征融合,未能充分利用更全面的全局特征,从而导致性能不够理想。Zhu
人能在几秒钟做出反应的时间都可以看作是感知范围内的事情。
联合嵌入预测架构 (JEPA) 为在紧凑的潜在空间中学习世界模型提供了一个引人注目的框架,但现有方法仍然脆弱,依赖于复杂的多项损失、指数移动平均、预训练编码器或辅助监督来避免表征崩溃。本文提出了 LeWorldModel (LeWM),这是第一个与目前唯一的端到端替代方案相比,LeWM 将可调损失超参数从六个减少到一个。LeWM 可以在单个 GPU 上训练 1500 万个参数,只需几个小时即可完成

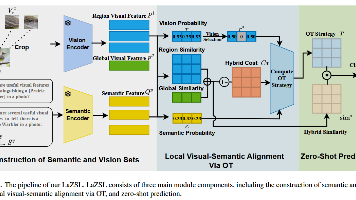
大规模视觉-语言模型(VLMs),例如 CLIP,通过利用大规模的视觉-文本配对数据,在零样本学习(ZSL)中取得了显著成功。然而,这些方法通常缺乏可解释性,因为它们计算的是整张查询图像与类别词嵌入之间的相似度,难以解释其预测结果。为了解决这一问题,一种可行的方法是开发具有可解释性的模型,为此,我们提出了 LaZSL,一种用于可解释零样本学习的局部对齐视觉-语言模型。。大量实验表明,我们的方法在可
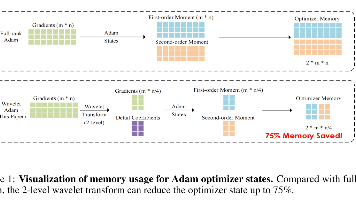
大型语言模型(LLMs)在多种自然语言处理任务中展现出了卓越的性能。然而,其庞大的参数规模在训练过程中带来了显著的内存挑战,。现。尽管这些方法有助于缓解内存限制,但与全秩更新相比,它们通常会产生次优的结果。在本文中,我们探索了超越低秩训练的内存高效方法,提出了一种名为。该方法通过将小波变换应用于梯度,显著降低了维护优化器状态所需的内存需求。我们证明了GWT能够与高内存消耗的优化器无缝集成,从而在不