




- @qq_51229257
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
周志华《机器学习》第五章“神经网络”是连接传统机器学习与深度学习的桥梁——它从模拟人脑神经元的基本模型出发,逐步构建多层网络,核心突破是BP算法的提出,最终延伸到深度学习的核心思想。本章的核心逻辑是:通过“神经元加权求和+激活函数”构建基本单元,用多层结构拟合非线性关系,靠BP算法优化参数,再通过不同网络拓扑适应不同任务。本文将从“基础模型→核心算法→代码实现→习题解答”四个维度,用通俗比喻和实例
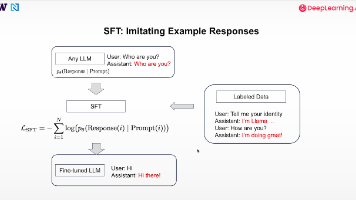
SFT 是给大模型“上课”的过程。简单来说,就是用少量高质量的“提示(Prompt)-响应(Response)”数据集,对预训练好的大模型进行定向优化。预训练数据量巨大(万亿级),目标是学习通用语言规律;SFT 数据量小(几千到上亿),目标是学习特定任务(如数学解题、代码生成)或规范模型行为。训练快、成本低,能快速让模型掌握基础指令能力。SFT 是 LLM 从“通用语言理解”走向“指令遵循”的关键
【代码】webpack serve 配置问题TypeError: Class constructor ServeCommand cannot be invoked without 'new'
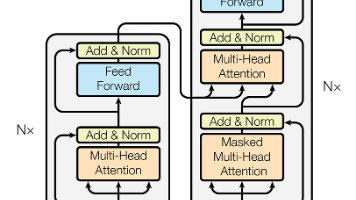
今天开始学习DataWhale组队学习fun-transformer,今天学习task2 transformer 简述!【教程地址】【开源地址】你有个朋友,他特别厉害,能听懂你说的话,还能用另一种语言把意思准确地翻译出来。Transformer模型就像是这样一个超级聪明的“翻译官”,它能够理解语言,并且把一种语言转换成另一种语言,或者完成其他和语言相关的任务,比如总结文章、回答问题等等。词嵌入:给

第三章的核心是“揭秘LLM的底层逻辑”——从统计语言模型的概率计算,到Transformer的注意力机制,再到实际应用中的提示工程、分词、模型选型,每一个知识点都是构建智能体“大脑”的关键。理解这些原理,能帮助我们更好地设计提示词、选择合适的模型、规避幻觉等局限,为后续智能体的构建和优化打下坚实基础。LLM的本质是“通过海量数据学习语言规律和世界知识,再通过自回归生成文本”,而Transforme
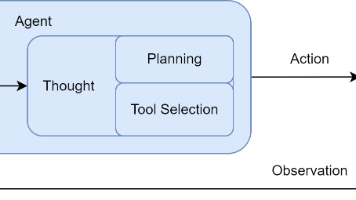
能够通过传感器感知环境、自主通过执行器采取行动,以达成特定目标的实体。环境(Environment):智能体所处的外部场景,比如自动驾驶的“道路交通”、交易算法的“金融市场”、智能旅行助手的“航旅服务网络”。传感器(Sensors):感知环境的“触角”,可以是物理设备(摄像头、雷达),也可以是虚拟工具(API返回数据、用户输入)。例如旅行助手通过解析航旅API获取机票信息,就是传感器在工作。
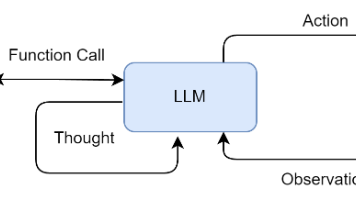
第四章通过三个经典范式,构建了智能体“从决策到落地”的完整技术链条:ReAct 解决“动态环境中的步进决策”,Plan-and-Solve 解决“结构化任务的高效执行”,Reflection 解决“高质量输出的迭代优化”。三者并非互斥,而是可根据场景灵活组合,形成更强大的混合架构。代码实现的核心是“模块化封装”——LLM客户端提供通用调用能力,工具层提供与外部世界交互的接口,范式层实现核心决策逻辑
过度乐观?图灵低估了“常识与世界知识”的体量。现代LLM参数量已超10¹¹,仍难言通过严格图灵测试。可证伪性?图灵测试本质是黑箱行为主义,忽视内部机制;Searle“中文屋”思想实验正是针对此。性别与伦理早期游戏用“男女角色扮演”如今看存在刻板印象,可改用更中性设定。ESP插曲虽显幽默,却提示:测试环境必须排除信息泄露与人类超能力。工程启示图灵70年前已提出“预训练+微调”范式(儿童机→教育),与

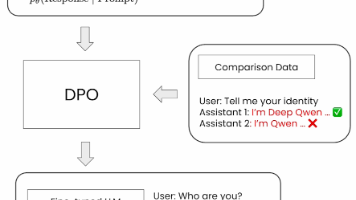
定位:不用复杂奖励模型,靠正负样本就能调模型行为的“轻量优化方法”;优势:改行为(如换身份)高效,还能提升模型能力,比SFT更懂“偏好”;落地关键:数据要高质量(正负样本对比明确),超参数(尤其是β)要调好,避免过拟合;实践价值:小到改模型身份,大到优化安全响应,都能用,而且计算成本不高(小模型CPU也能跑流程)。一句话:想让模型“按你的偏好做事”,又不想搞太复杂,DPO就是首选——这也是它在LL
第三章的核心是“揭秘LLM的底层逻辑”——从统计语言模型的概率计算,到Transformer的注意力机制,再到实际应用中的提示工程、分词、模型选型,每一个知识点都是构建智能体“大脑”的关键。理解这些原理,能帮助我们更好地设计提示词、选择合适的模型、规避幻觉等局限,为后续智能体的构建和优化打下坚实基础。LLM的本质是“通过海量数据学习语言规律和世界知识,再通过自回归生成文本”,而Transforme