




- @qq_51167531
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录1.数据采集和标记2.特征选择3.数据清洗4.模型选择5.模型训练6.模型测试7.模型保存与加载8.实例(手写数字识别)1.数据采集和标记2.特征选择3.模型训练4.模型测试5.模型保存与加载6.上述sk-learn模型以及模型参数1.数据采集和标记先采集数据,再将数据进行标记作用:尽可能多的采集的不同的数据,防止出现偶然性,使得采集到的数据具有代表性,才能保证最终训练出来的模型的准确性。2.
给定两个字符串text1和text2,返回这两个字符串的最长的长度。如果不存在,返回0。一个字符串的是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。例如,"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。两个字符串的是这两个字符串所共同拥有的子序列。
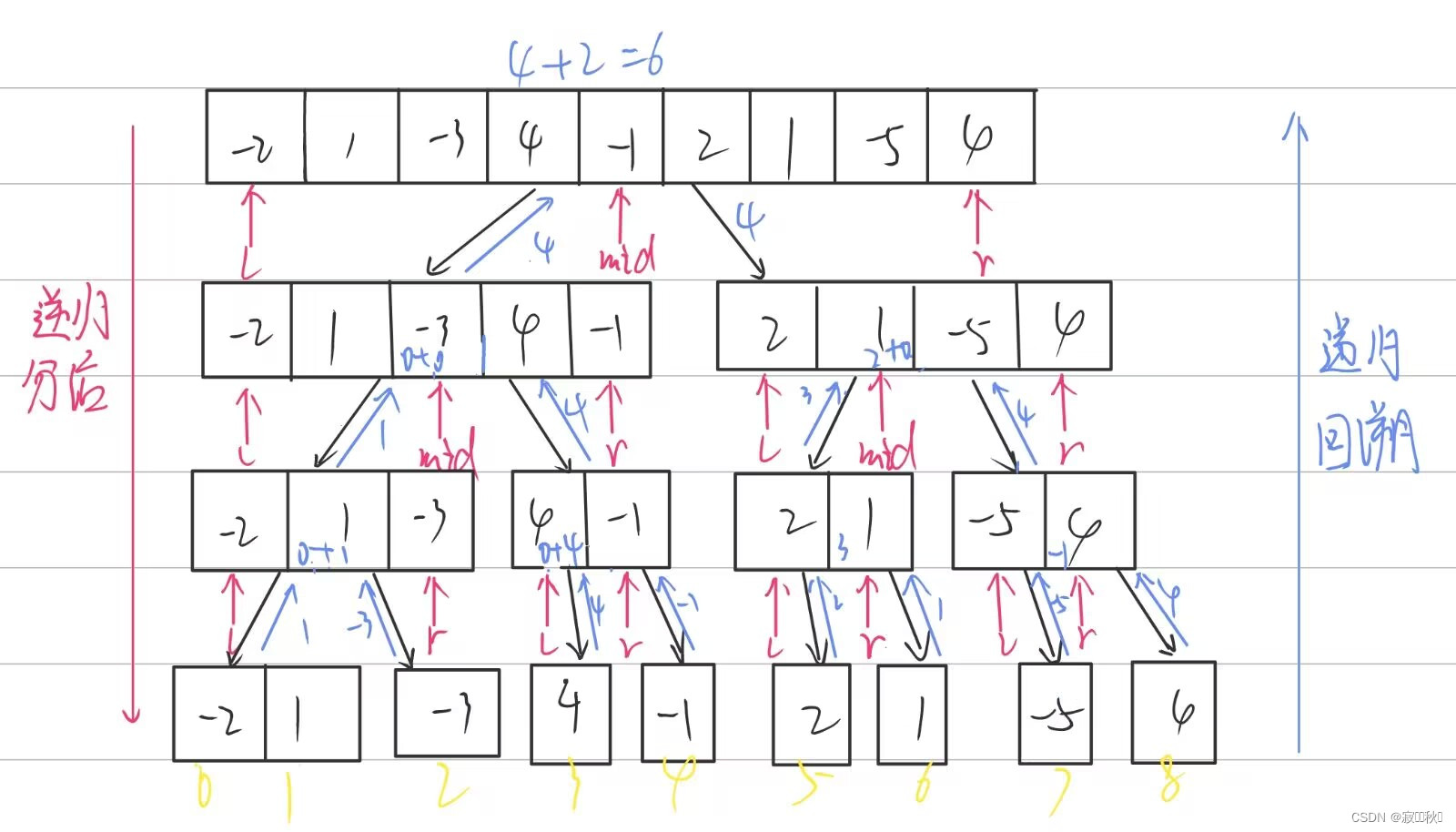
给你一个整数数组nums,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。是数组中的一个连续部分。
伪代码(Pseudocode)是一种算法描述语言。使用伪代码的目的是为了使被描述的算法可以容易地以任何一种编程语言(Pascal,C,Java,etc)实现。因此,伪代码必须结构清晰、代码简单、可读性好,并且类似自然语言。 介于自然语言与编程语言之间。 它以编程语言的书写形式指明算法的职能。相比于程序语言(例如Java, C++,C, Dephi 等等)它更类似自然语言。它是半角式化、不标准的语
1.缺失值产生产生原因缺失值的产生原因多种多样,主要分机械原因和人为原因。机械原因是由机械导致的数据缺失,比如数据存储的失败、存储器损坏、机械故障导致某段时间的数据未能收集(对于定时数据采集而言)。人为原因是由人的主观失误、历史局限或有意隐瞒造成的数据缺失。2.观察数据是否存在缺失值当我们拿到一个数据集时,我们无法第一时间看出数据集中是否有缺失值,因此本次博客主要介绍7中方法来观察数据集中是否存在