- @qq_50213874
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【摘要】阿里巴巴高德与西安交通大学联合提出自动驾驶新范式FutureSightDrive,通过"时空思维链"技术让AI直接生成未来场景的视觉预测图(含车道线、车辆位置等时空信息),实现端到端视觉推理。该方法突破传统"图像→文字→决策"的局限,以0.3%的低成本解锁视觉语言模型的图像生成能力,在nuScenes数据集上轨迹规划误差降低35%,碰撞率下降40%,
阿里高德与西安交大联合研发的FutureSightDrive系统,创新性地提出"时空思维链"(Spatio-Temporal CoT)技术,突破传统自动驾驶模型依赖文本推理的局限。该系统让AI直接在视觉层面模拟未来路况,通过"骨架-主体-细节"的渐进式方式生成预测图像,实现更精准的路径规划。实验数据显示,该方法使碰撞风险降低31%,在nuScenes等测试基
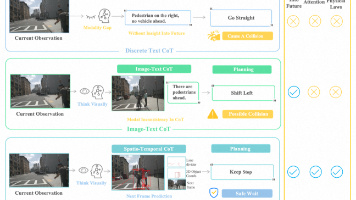
视觉语言模型(VLMs)因其强大的推理能力,在自动驾驶领域受到日益广泛的关注。然而,现有VLMs通常采用针对特定场景设计的离散文本思维链(Chain-of-Thought, CoT),这种表征本质上是对视觉信息的高度抽象和符号化压缩,可能导致空间-时间关系模糊以及细粒度信息丢失。自动驾驶是否更适合通过真实世界模拟与想象建模,而非纯粹依赖符号逻辑?本文提出一种时空思维链(spatio-tempora
视觉语言模型(VLMs)因其强大的推理能力,在自动驾驶领域受到日益广泛的关注。然而,现有VLMs通常采用针对特定场景设计的离散文本思维链(Chain-of-Thought, CoT),这种表征本质上是对视觉信息的高度抽象和符号化压缩,可能导致空间-时间关系模糊以及细粒度信息丢失。自动驾驶是否更适合通过真实世界模拟与想象建模,而非纯粹依赖符号逻辑?本文提出一种时空思维链(spatio-tempora
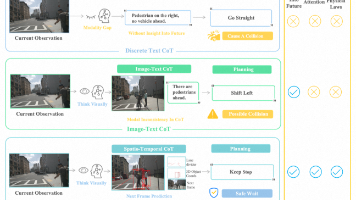
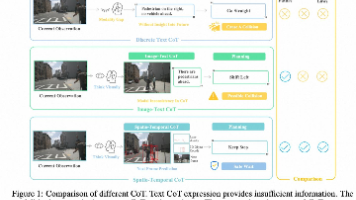
视觉语言模型(VLMs)因其强大的推理能力,在自动驾驶领域受到日益广泛的关注。然而,现有VLMs通常采用针对特定场景设计的离散文本思维链(Chain-of-Thought, CoT),这种表征本质上是对视觉信息的高度抽象和符号化压缩,可能导致空间-时间关系模糊以及细粒度信息丢失。自动驾驶是否更适合通过真实世界模拟与想象建模,而非纯粹依赖符号逻辑?本文提出一种时空思维链(spatio-tempora
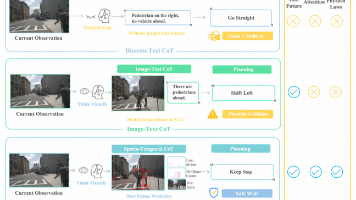
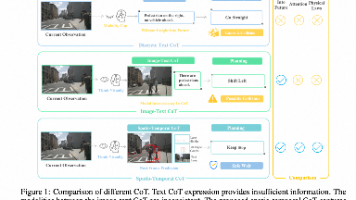
视觉语言模型(VLMs)因其强大的推理能力,在自动驾驶领域受到日益广泛的关注。然而,现有VLMs通常采用针对特定场景设计的离散文本思维链(Chain-of-Thought, CoT),这种表征本质上是对视觉信息的高度抽象和符号化压缩,可能导致空间-时间关系模糊以及细粒度信息丢失。自动驾驶是否更适合通过真实世界模拟与想象建模,而非纯粹依赖符号逻辑?本文提出一种时空思维链(spatio-tempora
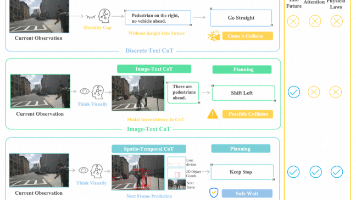
视觉语言模型(VLMs)因其强大的推理能力,在自动驾驶领域受到日益广泛的关注。然而,现有VLMs通常采用针对特定场景设计的离散文本思维链(Chain-of-Thought, CoT),这种表征本质上是对视觉信息的高度抽象和符号化压缩,可能导致空间-时间关系模糊以及细粒度信息丢失。自动驾驶是否更适合通过真实世界模拟与想象建模,而非纯粹依赖符号逻辑?本文提出一种时空思维链(spatio-tempora