




- @qq_45732909
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因此,如果在模型训练过程中,出现预测概率为0的情况,即模型完全错误地预测了某个样本的类别,那么使用交叉熵损失函数就会遇到问题,因为在对数运算中,0是无意义的,对数值为0的情况没有定义,这会导致计算出错。为了避免这样的数值稳定性问题,在实际应用中,通常会采用一些数值稳定的技巧来实现softmax函数,例如将输入向量中的每个元素减去向量中的最大值,或者使用一些近似方法等。因此,尽管最大概率在许多情况下

softmax(o)给出的分布⽅差,并与softmax交叉熵损失l(y, yˆ)的⼆阶导数匹配。Softmax函数可以将一组任意实数值转换为一个概率分布,它的输出值是各个类别的概率估计。如果我们用softmax函数得到的概率分布与真实分布非常相似,那么交叉熵损失函数就会趋近于0,表示模型的预测结果和真实结果非常接近。而关于softmax函数的方差,它可以衡量这个概率分布的分散程度,也就是模型对不同

在冷启动情况下,系统需要处理缺乏历史数据的情况,而在热启动情况下,系统可以充分利用历史数据来进行推荐。解决冷启动问题是推荐系统领域的一个重要挑战,需要创新的方法和技术来应对。在热启动阶段,推荐系统可以依赖用户的历史行为和交互数据来进行推荐,因为系统已经了解了用户的兴趣和喜好。在机器学习和推荐系统领域,“冷启动”(Cold Start)和"热启动"(Warm Start)是两个常用的概念,它们用来描
(也叫Glorot uniform initialization) 我觉得是特殊的uniform。
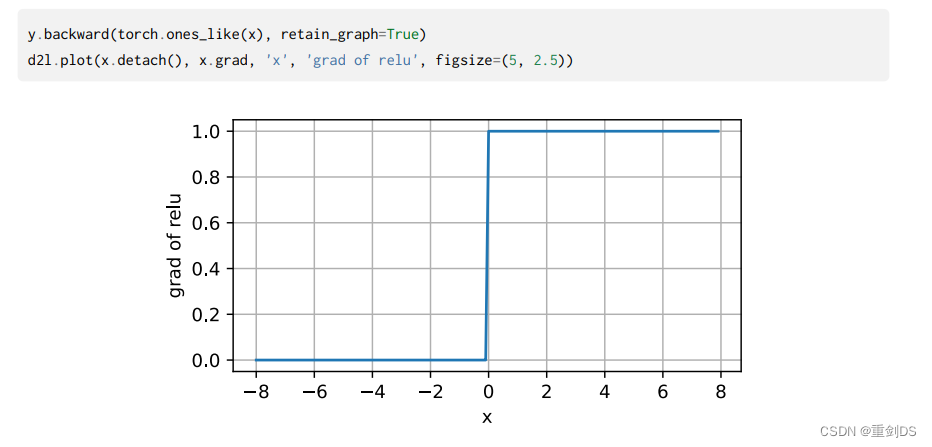
对于简单的问题,单隐层网络可能足够,而对于更复杂的问题,需要更深的网络结构,并且可能需要更多的神经元来确保网络的表达能力。具体来说,假设X是一个n×d的矩阵,W是一个d×h的矩阵,b是一个1×h的行向量,那么XW是一个n×h的矩阵,b也可以被扩展为一个n×h的矩阵,使得在矩阵加法时可以直接与XW相加。但是,在每个线性段内部,都是连续的,也就是说,对于每个线性段,输出在该段上是连续的。类似于复合函数
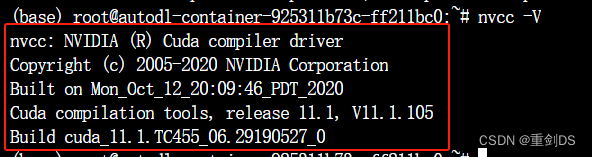
nvcc -V的版本号是CUDA工具包的版本信息,而nvdia-smi上面写的很清楚,是cuda的版本号了。都与NVIDIA GPU相关,但它们提供的信息和功能有所不同。
在冷启动情况下,系统需要处理缺乏历史数据的情况,而在热启动情况下,系统可以充分利用历史数据来进行推荐。解决冷启动问题是推荐系统领域的一个重要挑战,需要创新的方法和技术来应对。在热启动阶段,推荐系统可以依赖用户的历史行为和交互数据来进行推荐,因为系统已经了解了用户的兴趣和喜好。在机器学习和推荐系统领域,“冷启动”(Cold Start)和"热启动"(Warm Start)是两个常用的概念,它们用来描
题目详情给定某数字A(1≤A≤9)以及非负整数N(0≤N≤100000),求数列之和S=A+AA+AAA+⋯+AA⋯A(N个A)。例如A=1, N=3时,S=1+11+111=123。要求时间限制: 200 ms内存限制: 64 MB代码长度限制: 16 KB输入格式:输入数字A与非负整数N。输出格式:输出其N项数列之和S的值输入样例:1 3输出样例:123个人思路这...
题目详情凤湖小学二年级的陈老师吃惊地发现班上的同学竟然可以分成三类,一类总是可以正确地完成三位整数加减法(GroupA);一类总是可以正确地完成三位整数的加法,但对于减法运算来说,总是忘记借位的处理(GroupB);剩下的人总是忘记加法的进位,也总是忘记减法的借位(GroupC)。现在请给出一次陈老师在课堂提问时,同学们会给出的回答。实现时请基于下面的基类框架class Group{public:
题目详情将一个正整数N分解成几个正整数相加,可以有多种分解方法,例如7=6+1,7=5+2,7=5+1+1,…。编程求出正整数N的所有整数分解式子。要求时间限制: 800 ms内存限制: 64 MB代码长度限制: 16 K输入格式:每个输入包含一个测试用例,即正整数N (N>0&&N<=30)。输出格式:按递增顺序输出N的所有整数分解式子。递增顺序...