




- @qq_44815135
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细解析了PyTorch中nn.Embedding的实现原理。通过设定小规模参数示例(batch_size=2, seq_len=3, vocab_size=5, hidden_size=4),展示了embedding层的查表过程:每个token id对应一个固定维度的向量,输入序列经过查表后转换为(batch_size, seq_len, hidden_size)的三维张量。文中还提供了完整

image_path: 图片路径的列表(可能是字典格式的列表)。: 已经编译好的 TensorRT ViT 引擎文件路径(.enginestream: CUDA 流,用于异步推理。

文字 (Human-readable)│▼Tokenizer│input_ids (整数序列) ←—— token ID│▼Embedding 层│embedding 向量 (连续向量序列)│▼│输出结果(预测下一个 token、生成文本等)

这是 Transformer 可以处理的统一格式。不同模态通常先经过对应的。(例如图像、音频、视频)

把图像路径和文本拼成结构化输入 → tokenizer 加入视觉占位符 → 用 ViT 特征替换这些位置的 token → 构建 prompt table 映射 → 调用 Qwen-VL 模型生成 → 解码输出文本。阶段数据结构示例输入input_textinput_text="这是什么?[{"image":"img.png"}, {"text":"这是什么?"}]query带特殊token的字符

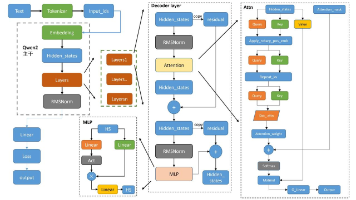
Qwen2.5是阿里云最新推出的开源大型语言模型系列,相比Qwen2,新版本在多个方面实现了显著提升,包括知识掌握、编程能力、数学能力以及指令执行等。2. input_ids → Embedding 层将 token id 查表得到向量:这是 Transformer 第 0 层的初始特征。每层结构:每层都更新 hidden_states:4. Transformer 最后一层输出 → Fi
在卷积神经网络(Convolutional Neural Network,CNN)中,下采样和上采样是指特征图的空间尺寸变化操作。

这种保存形式将模型的参数保存为一个字典,其中包含了所有模型的权重和偏置等参数。状态字典保存了模型在训练过程中学到的参数值,而不包含模型的结构。可以使用这个字典来加载模型的参数,并将其应用于相同结构的模型。序列化模型保存了模型的完整信息,可以完全恢复模型的状态,包括模型的结构、权重、偏置以及其他相关参数。这种保存形式非常适用于仅保存和加载模型的参数,而不需要保存和加载模型的结构。这种保存形式适用于需
