




- @qq_44528283
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当前提升大语言模型(LLM)推理能力的研究方法主要可划分为两类:(1)基于记忆增强的方法。该方法聚焦于优化模型对外部世界知识的检索与利用机制,尤其针对未内化于模型参数的知识体系,例如检索增强生成(Retrieval-Augmented Generation, RAG),通过动态接入外部知识库强化信息召回能力。(2)基于推理优化的方法。该方法旨在改进模型自身的逻辑推演过程,例如引入思维链(Chain
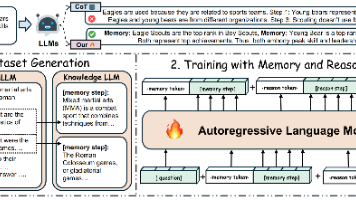
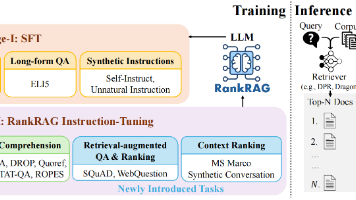
检索增强生成(RAG)技术被广泛应用于定制化的大语言模型(LLMs),使其能够有效处理长尾知识、集成最新信息,并适应特定领域或任务需求,且无需调整模型权重。其流程包含两个核心阶段:首先,基于语义嵌入的检索器从文档集合或外部知识源中,查询并检索语义最相关的k个上下文片段;随后,大语言模型读取这些检索到的上下文片段,据此生成最终答案。这种技术可以显著增强大语言模型在专业与时效性场景下的知识利用能力。
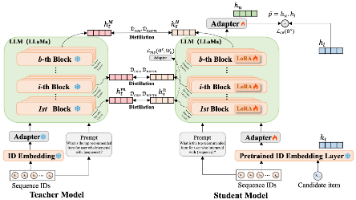
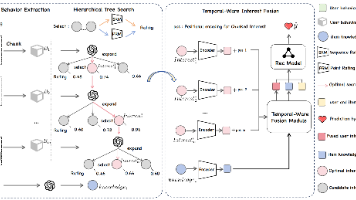
序列推荐任务旨在通过用户过往的交互数据,来预测用户可能与之互动的下一个行为,因此这类模型通过建模分析用户的行动序列,揭示更复杂的行为模式和时间动态。近期研究表明,将大语言模型引入推荐系统逐渐成为研究热门,无论是将序列推荐视为语言模型的语义建模,还是作为用户表征的一种方法,都使大语言模型对序列推荐任务产生了深远影响。但是,由于大模型的庞大,在现实生活中大部分平台上应用大模型显得低效且不切实际,如何平
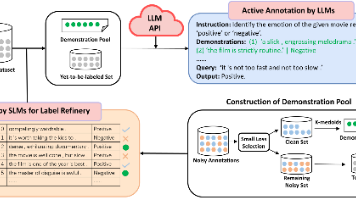
传统的主动学习,降低了第一步的标注成本,通过迭代标注小部分数据,然后通过模型的Uncertainty(或Feature-based Diversity)进行校验,筛选剩余有价值的样本进行再标注。但仍存在两个问题,首先是少量标注其实很难训练很好的模型,影响后续筛选的步骤,其次传统AL还是需要大量的人力成本,目前的AL论文大部分都需要标注10%~50%以上的数据才能达到较好的性能。(1)数据标注依然重
推荐系统(Recommendation Systems, RS)已在电子商务、影视推荐及音乐发现等领域实现广泛部署,显著优化了用户体验。用户行为建模作为核心环节,其关键在于解码行为序列中蕴含的细粒度偏好信号。传统模型(如DIN、DIEN)主要依赖用户行为的离散标识符特征语义理解缺失:无法有效捕捉用户与项目的语义关联,在数据密集型场景中形成认知鸿沟;行为完整性忽视:仅利用局部历史行为片段,导致偏好建
本篇博客主要总结一下博主看过的人工智能领域的一些前沿论文,期待与大家一起进行交流探讨,列表中有超链接的是已经进行了精读的完整笔记,没有超链接的是进行了泛读的论文,博主会快马加鞭进行更新滴!请耐心等待博主嘿嘿,有什么比较好的论文也欢迎大家推荐给我啦,和大家一起学习共同进步!
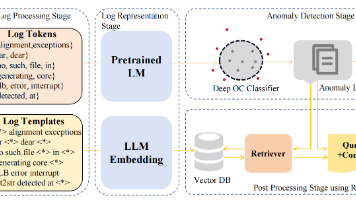
随着微服务架构的复杂性增加,故障和异常的发生频率也随之上升,这对用户体验和系统稳定性构成了威胁。传统的日志分析方法依赖于人工,但在系统日益复杂的情况下,这种方法的效率和有效性都在下降。因此,自动化的日志分析成为了异常检测和故障预测的关键手段。(1)在实验部分将数据集分成若干组,每次都是训练前一组,然后在下一组上做测试。(2)有二次判断的过程,对初步异常检测的结果进行再判断,避免分类错误。
文章目录@[toc]练习题五一、选择题二、填空题三、判断题四、简答题练习题六一、选择题二、填空题三、判断题四、简答题练习题七一、选择题二、填空题三、判断题四、简答题练习题八一、选择题二、判断题三、简答题练习题五一、选择题1.【单选题】以下不是正确置换的是(C)A. { a/x, f(b)/y, w/z }B. { g(a)/x, f(b)/y }C. { g(y)/x, f(x)/y }D. {z
文章目录@[toc]练习题一一、选择题二、填空题三、简答题练习题二一、选择题二、填空题三、判断题四、简答题练习题三一、选择题二、填空题三、判断题四、简答题练习题四一、选择题二、填空题三、判断题四、简答题练习题一一、选择题1.【多选题】认识智能的观点有(ABC)A.思维理论B.知识阈值理论C.进化理论D.行为理论2.【多选题】思维方式有(ACD)A. 抽象思维B. 逆向思维C. 形象思维D.灵感思维
1.train_loss 不断下降,val_loss(test_lost) 不断下降说明网络训练正常,最好情况2.train_loss 不断下降,val_loss(test_lost) 趋于不变说明网络过拟合,可以添加dropout和最大池化max pooling3.train_loss 趋于不变,val_loss(test_lost) 不断下降说明数据集有问题,建议重新选择4.train_los