- @qq_43776757
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当AI学会“看图说话”,从 CLIP 到 LLaVA/Qwen:揭秘多模态大模型(MLLM)的“视觉基石”;温馨提示:文末有我们最喜欢的两个:经典环节1--人话总结,经典环节2--测验环节;可快速了解本篇论文CLIP。

大家好,今天是2025年12月17日,周三,还有不到2个月就过年了,我们加加速。所以今天咱们不追热点,沉下心来,回过头去扒一扒 LLaVA。你会发现,现在的很多“黑科技”,其实都是它当年玩剩下的“反常识”套路。把这个基石踩稳了,后面不管出什么新模型,你都能一眼看透本质。

当AI学会“看图说话”,从 CLIP 到 LLaVA/Qwen:揭秘多模态大模型(MLLM)的“视觉基石”;温馨提示:文末有我们最喜欢的两个:经典环节1--人话总结,经典环节2--测验环节;可快速了解本篇论文CLIP。
从ChatGPT到DeepL,现代AI的基石都源于2017年的一篇论文。它不仅提出了Transformer,更用一种极其优雅的方式,颠覆了我们对序列建模的全部认知。
当AI学会“看图说话”,从 CLIP 到 LLaVA/Qwen:揭秘多模态大模型(MLLM)的“视觉基石”;温馨提示:文末有我们最喜欢的两个:经典环节1--人话总结,经典环节2--测验环节;可快速了解本篇论文CLIP。
方法一:watch -n 0.5 nvidia-smiwatch -n 0.5 nvidia-smi:0.5代表每隔0.5秒刷新一次GPU使用情况,同理,每隔1秒刷新,则使用:watch -n 1 nvidia-smi方法二:nvidia-smi -l 1,每1秒刷新一次,不建议使用watch查看nvidia-smi,watch每个时间周期开启一个进程(PID),查看后关闭进程,会影响cuda操作
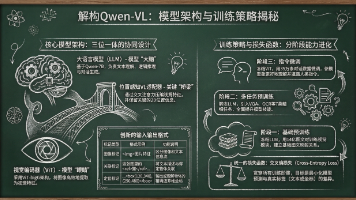
今天是 2025 年 12 月 22 日,周一。眼瞅着双旦将至,快过年了,咱们解读论文的节奏也得提提速!想象一下,有一位博览群书、才华横溢的思想家,但他的一生都只在纯文字的世界里度过,从未见过真实世界的色彩与形态。这就像是传统的大语言模型(LLM),它们在文本理解和生成上能力超群,却是一个“失明”的天才。现在,让我们给这位思想家安上一双锐利的眼睛,让他不仅能阅读万卷书,还能看见万物,理解图像中的信
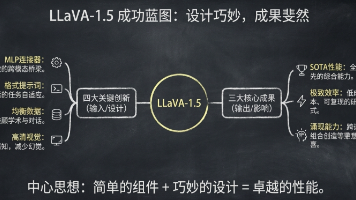
导语:今天是 2025年12月21日,周日。眼瞅着2025年的“余额”只剩最后一些日子,马上就要过年了!大家是不是都在忙着赶年前的最后并在 KPI,或者已经开始憧憬即将到来的春节假期了?摘要:它是如何用极少的数据、极简单的架构,打败复杂的庞然大物的?本文带你深入解构 LLaVA-1.5 的“视觉-语言”魔法。
大家好,今天是2025年12月17日,周三,还有不到2个月就过年了,我们加加速。所以今天咱们不追热点,沉下心来,回过头去扒一扒 LLaVA。你会发现,现在的很多“黑科技”,其实都是它当年玩剩下的“反常识”套路。把这个基石踩稳了,后面不管出什么新模型,你都能一眼看透本质。
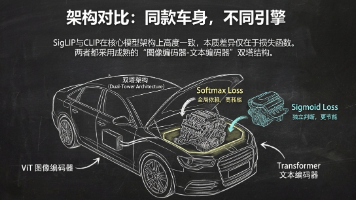
今天讲的是 训练策略(重点是损失函数),跟模型架构没有关系导读:在AI领域,“大力出奇迹”似乎是永恒的真理。更大的模型、更大的显存、更大的Batch Size...但在谷歌最新的SigLIP论文中,研究人员用一个简单的数学变换证明:有时候,做得更少,反而能做得更好。 本文将带你深入底层,看Sigmoid如何四两拨千斤,取代Softmax重塑多模态训练。