




- @qq_42578970
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
由于视频处理与语言处理存在一定的相似性,都是连续的且要关注上下文,因此作者设计出了一种新的注意力机制,同时关注该帧不同区域的信息和前后几帧的信息,实现无卷积的视频分类。在上图中,蓝色为所要查询的格子,红色等其他颜色为注意力覆盖区域,没上色的表示计算注意力时没关注这些格子。传统的ViT只关注目前这一帧的其他区域,而本文会关注前后帧的信息。同时,本文关注的是Divided Space-Time Att

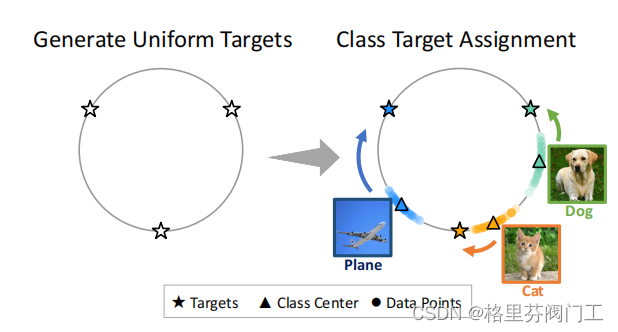
相比于直接对图像进行分类,本文更关注特征提取部分,通过令提取的不同类特征在超球面上尽可能远离,让属于同一类的特征尽可能靠近彼此,同时靠近分配到的一个锚点,来提高模型面对样本不平衡时的分类性能。...
每个元素都为实数的对角矩阵称为实对称矩阵,实对称矩阵必定相似于一个对角矩阵(对角线以外的元素全为0的矩阵),即存在可逆矩阵P,使得,且存在正交矩阵Q,使得实对称矩阵化为对角矩阵的步骤:1.找出全部特征值2.找出每个特征值对应的方程组,的基础解系,如果为k重根,那么基础解系必定有k个线性无关的特征向量。3.如果2中,存在某个特征值对应的多个特征向量不正交,那么就要正交化那k个向量,具体做法一般为施密
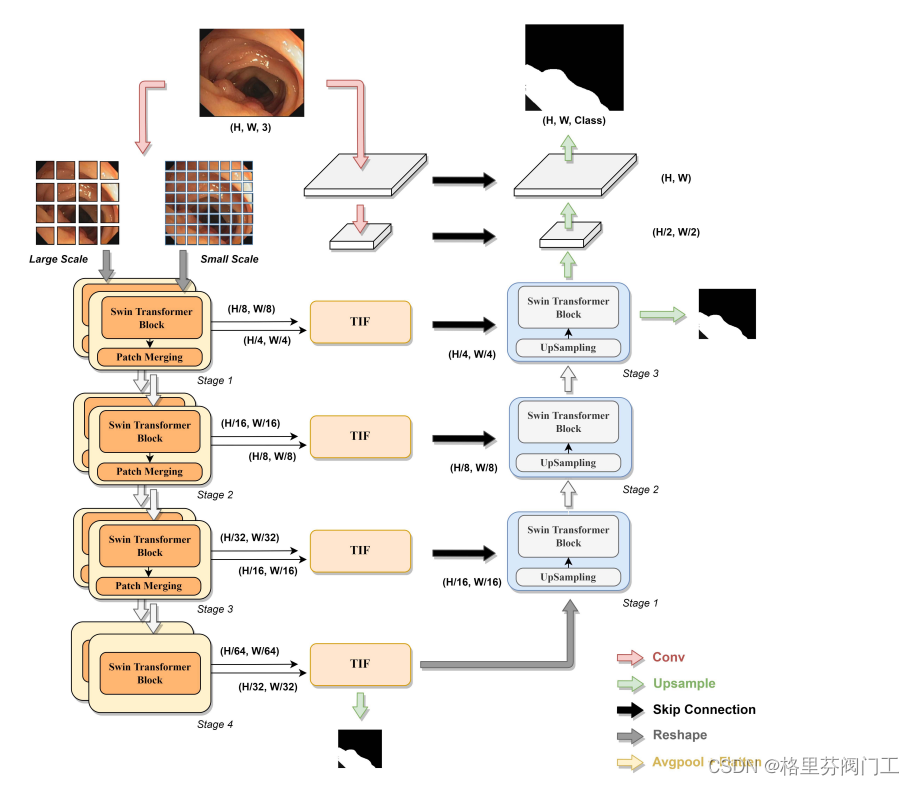
本文的用了双胞胎网络,通过不同的patch_size,关注不同尺寸的信息,然后利用TIF模块进行融合,解决ViT无法兼顾局部和全局的问题
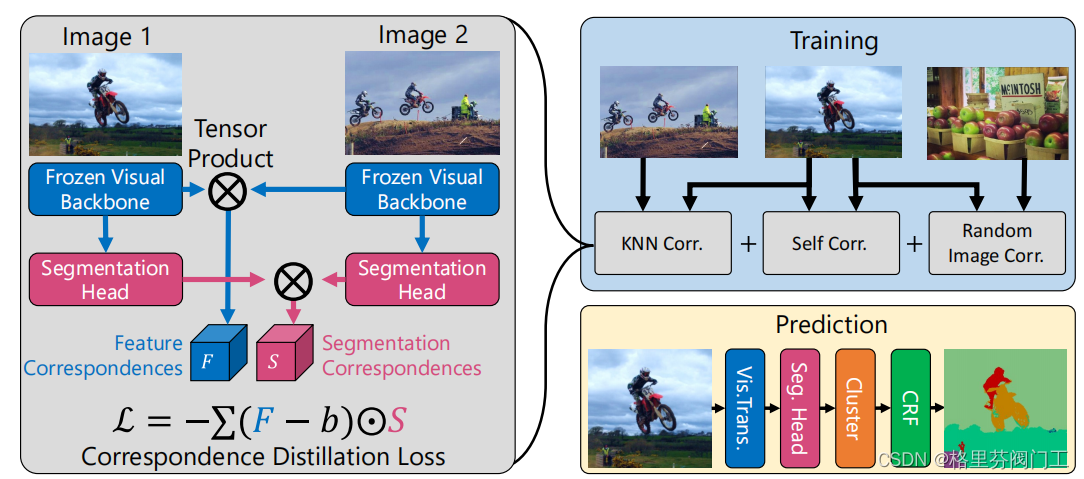
无监督语义分割因为训练时没有标注,所以需要让特征具有充分的语义信息的同时,让同一类物体对应的像素的特征足够紧凑。因此本文根据这两个特点,没有采用以往端到端的方式,而是将无监督语义分割拆分为提取特征和聚类两步。作者认为,目前的特征提取模块已经能很好地将同类特征放在一起了,因此本文创新点是通过全新的损失函数,鼓励模型将特征变得更加紧凑的同时不破坏不同分类之间的关系(大白话就是不能为了聚类而聚类,不能把
等价AB秩相同合同=等价+正负惯性指数相同相似=合同+特征值相同+主对角线元素之和相同+行列式的值相同等由此可见,等价到合同到相似,条件越来越苛刻,AB共同点越来越多
定义:对于(x0,y0),存在点邻域,邻域内任取x和y,有f(x,y)>=f(x0,y0),则为极小值点,有f(x,y)<=f(x0,y0),则为极大值点函数极值点一定是驻点,驻点不一定是极值点,驻点为两个偏导数存在且均为0的称为驻点令A=,B=,C=若AC-B^2>0,则为极值点,且A>0为极小值若AC-B^2<0,则不是极值点若AC-B^2=0,则进一步
均匀分布:在取值范围(a,b)内取得任意一点的概率相等记为X~U(a,b)数学期望E(X)为(a+b)/2,方差为(b-a)^2/12指数分布:若随机变量X的概率密度为则称X服从参数为λ的指数分布,记为X~e(λ)因此得到分布函数为个别教科书中,参数为θ=1/λ,在概率密度函数和分布函数中做同样的替换即可当参数为λ时,数学期望E(X)为1/λ,方差D(X)为1/λ^2正态分布(最最最最最重要!):
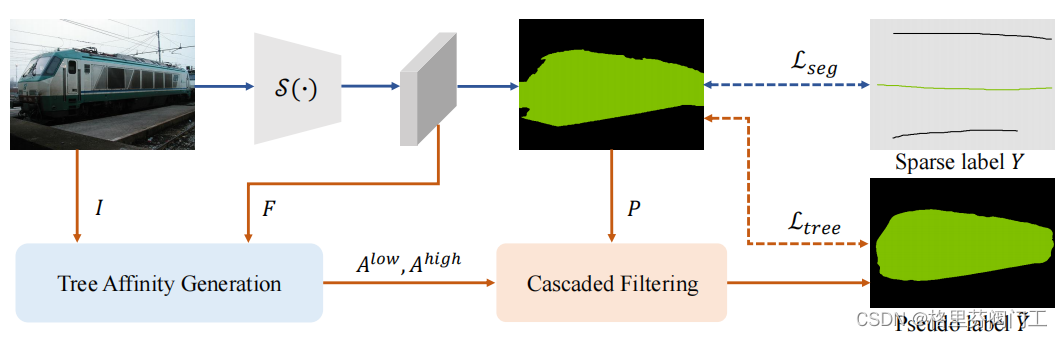
摘要首先解释一下Sparsely Annotated Semantic Segmentation(SASS),这种训练顾名思义就是标注地十分稀疏,只在画面的极少的像素上进行标注,模型要根据这稀少的标注学习分割。而本文提出了一种方法,先让模型进行传统的分割,计算一种传统的损失函数,将分割结果结合高层和低层信息进行修改,比较修改前后的分割结果计算损失函数。将两个损失函数相加可以方便快捷地训练模型,在S
协方差:Cov(X,Y)=E{}相关系数:公式:Cov=E(XY)-E(X)E(Y)D(XY)=D(X)+D(Y)2Cov(X,Y)Cov(aX,bY)=ab*Cov(X,Y)Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)