




- @qq_41938259
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
用docker部署webstack导航网站-其一遇到的问题:webstack容器无法运行网站报错:No application encryption key has been specified
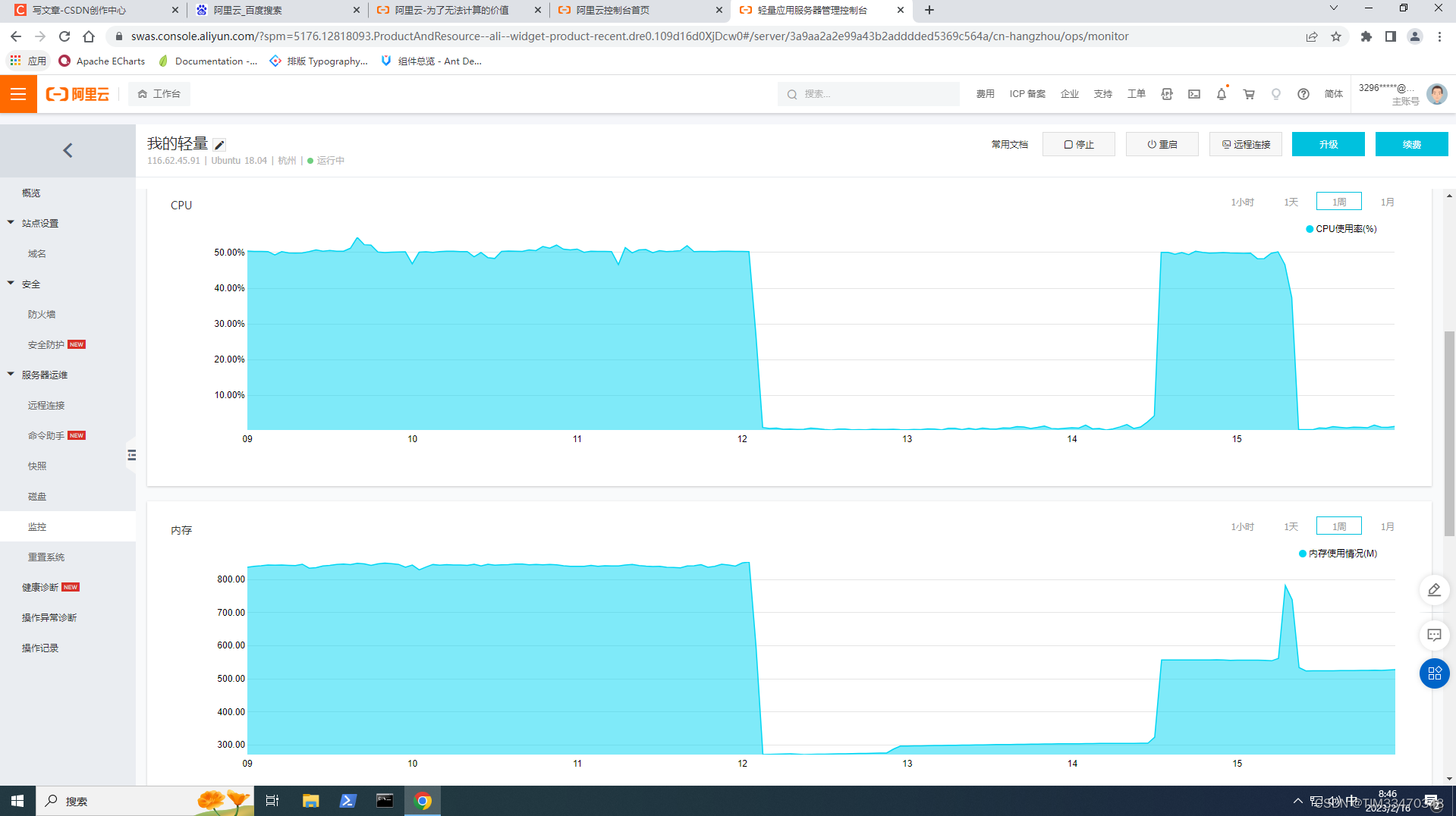
清理挖矿程序的基本步骤先用top命令查看cpu占用率大的进程的PID,再用systemctl status cpu占用率大的进程的PID命令查看守护进程地址,以用rm命令删除挖矿程序。在用rm命令删除挖矿程序前,应该检查是否存在后门,以防止坏东西通过后门再次侵入。所谓后门,我检查了路由条目和定时任务:是否有多出来的定时任务(非自己加入的定时任务)?是否有多出来的路由条目?是否是应为集群中其他的服务
第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全
今天上午10点45分的,感觉面试管看了我的简历和学校就觉得我菜吧,有点看不起人,然后说我都给了url也没写几句,我想我今天要好好改下简历。看了我的博客还觉的我是抄别人的。前天挂掉的是负责微信后台的,多是鼓励我,今天这个人嘲讽我居多,感觉就想走个流程吧,今天这个是腾讯云的。先是问下项目,做过的什么东西,他看了我的学生信息管理系统,什么也没说,然后开始问答。回忆一下没问了这些。进程通信(我回...
机器学习是人脸识别的根基,一张图片在计算机中存储首先是通过记录构成它的像素点的信息,包括像素的位置、RGB色彩以及灰度值等。在处理图像的过程中,图像也是通过矩阵的形式存放的,一个矩阵表示一张图片。通过对矩阵的翻转、平滑、膨胀等操作实现边缘检测和特征提取等操作。可以说,机器学习不仅是对于人脸识别,在整个人工智能的地位都是举足轻重的。机器学习是基于测试集构建的数学模型,我们一般会用概率统计模型作为..
首先这个项目是属于我的省级大创(大学生创新实验计划)的,最终实现的目标是可以上传图片作为人来能识别库,并且人脸识别结果用语音报出来。现在第一步,先实现数据库的对接,这一次用MySQL数据库,过几天也许会考虑改成Redis来存放,毕竟存放如数据库的是图片在服务器端的存放地址,而不可能是整个图片的信息;毕竟这是一个键值对,完全可以用Redis的String来存放。现在来具体介绍下views.p...
1.什么是数据清洗?在获得数据后并不能直接进行数据分析处理,为什么?因为得到的数据不一定完全准确,直接使用这些数据进行分析的话可能会产生不小的偏差。所以,我们需要数据清洗这个步骤。总而言之,数据清洗是要对脏数据进行处理。脏数据包括缺失的数据,异常的数据和不一致的数据三种。先讨论缺失值处理方法。2.缺失值处理的方法缺失值处理方法大致思路是删除法和插补法。缺失值处理的删除法删除法顾名思义,就是将含有缺
首先这个项目是属于我的省级大创(大学生创新实验计划)的,最终实现的目标是可以上传图片作为人来能识别库,并且人脸识别结果用语音报出来。现在第一步,先实现数据库的对接,这一次用MySQL数据库,过几天也许会考虑改成Redis来存放,毕竟存放如数据库的是图片在服务器端的存放地址,而不可能是整个图片的信息;毕竟这是一个键值对,完全可以用Redis的String来存放。现在来具体介绍下views.p...
机器学习是人脸识别的根基,一张图片在计算机中存储首先是通过记录构成它的像素点的信息,包括像素的位置、RGB色彩以及灰度值等。在处理图像的过程中,图像也是通过矩阵的形式存放的,一个矩阵表示一张图片。通过对矩阵的翻转、平滑、膨胀等操作实现边缘检测和特征提取等操作。可以说,机器学习不仅是对于人脸识别,在整个人工智能的地位都是举足轻重的。机器学习是基于测试集构建的数学模型,我们一般会用概率统计模型作为..
第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全