




- @qq_41072222
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
终于更新了!终于更新了!等了好久这本书总算是更新了。我一开始用的Python3.6以及pandas 0.23.4,使用第一版的时候总遇到语法不一致的问题。话不多说,我先大致介绍一哈,第二版的新内容:...
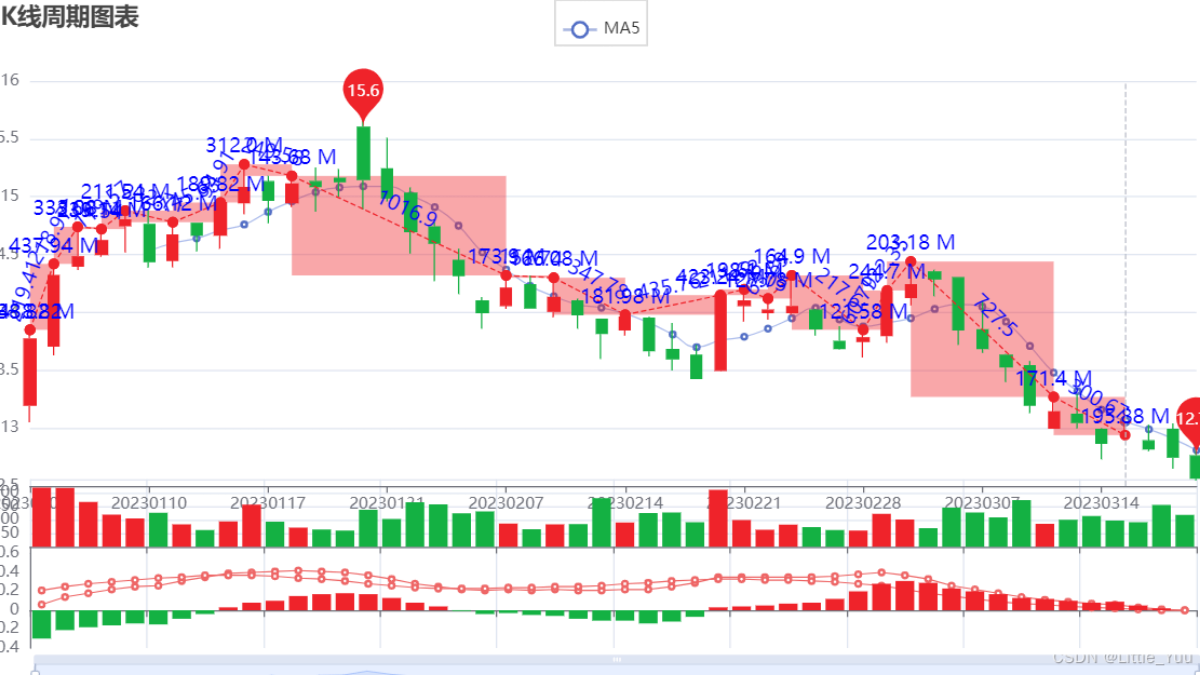
数据来源:tushare数据字段包含:日期,开盘价,收盘价,最低价,最高价,涨跌需要计算的数据:macd,diff,dea。
终于更新了!终于更新了!等了好久这本书总算是更新了。我一开始用的Python3.6以及pandas 0.23.4,使用第一版的时候总遇到语法不一致的问题。话不多说,我先大致介绍一哈,第二版的新内容:...
【代码】python交易明细分析工具。

@TOC一、在爬取公告之前需要了解一些基本信息(1)东方财富网是否需要登陆才能查看全部股票信息不需要二、使用selenium操作浏览器获取数据的基本流程(1)打开“东方方财富网>数据中心>公告大全>沪深A股公告”页面;(2)在“个股公告查询”输入框中数据需要查询的股票代码,并点击“查询”按钮;(3)此时浏览器会自动在新的窗口打开指定股票公告页面;(4)遍历所有公告...
文本分类数据集汇总名词解释一、“达观杯”文本智能处理挑战赛数据集1、数据格式2、测试集:test_set.csv数据集二数据集三参考文献名词解释(1)脱敏处理一、“达观杯”文本智能处理挑战赛数据集“达观杯”文本智能处理挑战赛数据集包含了两个文件,分别是:train_set.csv和test_set.csv。以下是关于这两个数据集的介绍1、数据格式2、测试集:test_set.csv数...
文本分类评价指标一、准确率(Accuracy)二、精确率(Precision)三、召回率(Recall)四、F1参考文献一、准确率(Accuracy)准确率关注整体效果,只适合均衡的数据。准确率公式如下:Accuracy=预测正确的样本数总样本数Accuracy=\frac{预测正确的样本数}{总样本数}Accuracy=总样本数预测正确的样本数二、精确率(Precision)精确率关...
特征提取参考文献参考文献1、sklearn——CountVetorizer详解
写在前面遇到同样问题的朋友,请直接看下面已经跑通的代码:%%writefile read_datasets.py#一、读取达观杯竞赛数据import pandas as pddef read_DC_dataset(filename,index):dataset=pd.read_csv(filename,header=0,index_col=index)return ...
数据来源:tushare数据字段包含:日期,开盘价,收盘价,最低价,最高价,涨跌需要计算的数据:macd,diff,dea。