
写文章




- @qq_39412605
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
oracle备份恢复
oracle备份恢复概念:1、备份定义备份就是把数据库复制到转储设备的过程。其中,转储设备是指用于放置数据库副本的磁带或磁盘。通常也将存放于转储设备中的数据库的副本称为原数据库的备份或转储。备份是一份数据副本2、备份分类从物理与逻辑的角度来分类:从物理与逻辑的,备份可以分为物理备份和逻辑备份。物理备份:对数据库操作系统的物理文件(数据文件,控制文件和日志文件)的备份。物理备份又可以分为脱机备份(冷

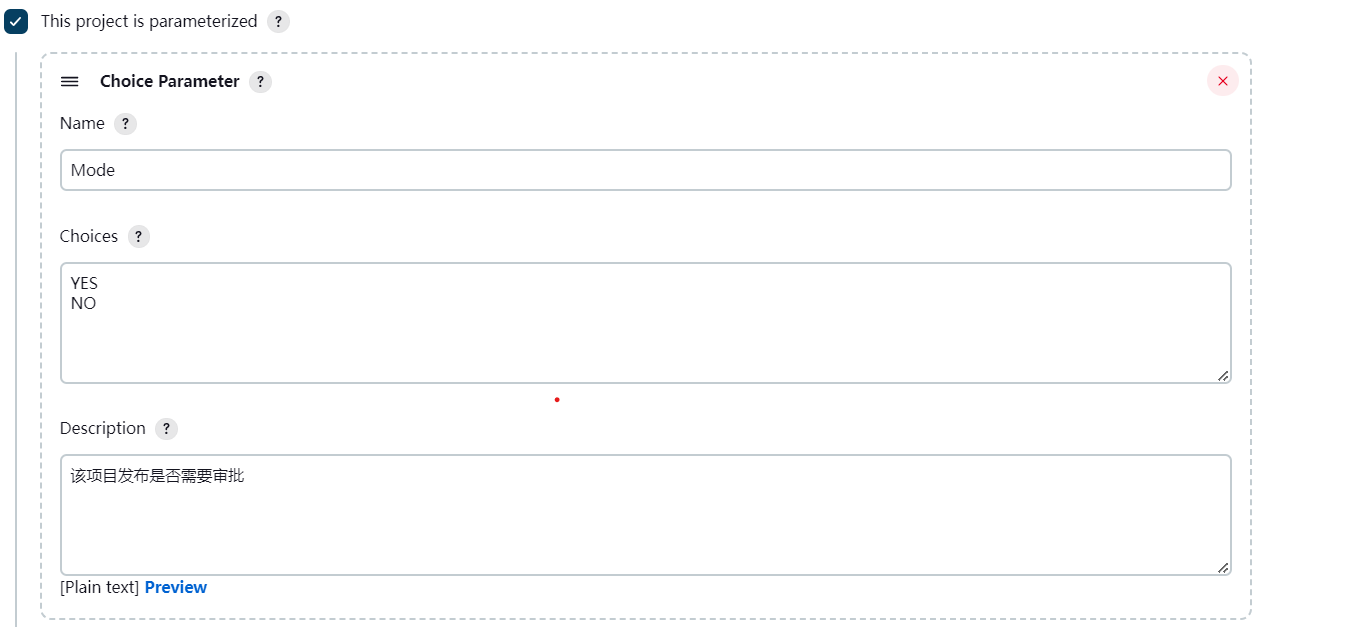
jenkins发布使用邮件添加审批
在这里插入图片描述](https://img-blog.csdnimg.cn/418fc89bfa89429783a1eb37d3e4ee26.png#pic_center。首先安装好Email Extension Plugin插件并在 system下配置好邮件。然后配置流水线需要的参数。
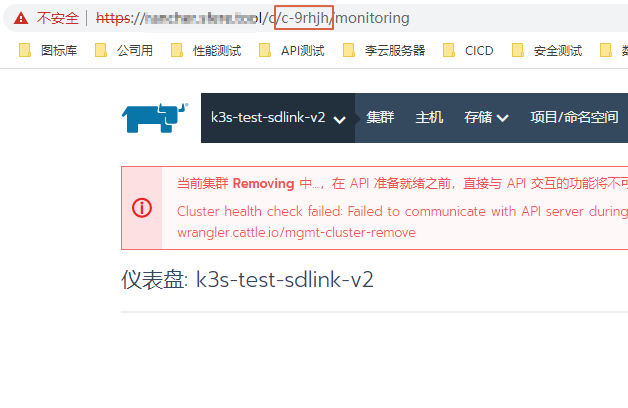
rancher上强制删除集群
有时候,我们会出现,虚拟机先删除了,然后才想起来rancher里还有个集群没删掉,这个时候,再通过rancher的界面去删除托管集群,往往会一直卡在“当前集群Removing中” 那么这种情况下,该如何处理呢?输入命令kubectl get clusters.management.cattle.io 就可以看到我们卡住的集群。1.点击待删除集群的名字,进入集群的详情页,复制URL中C/后面的字符,
到底了