




- @qq_30612221
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了在NVIDIA RTX 4060Ti 16G显卡上部署通义千问3-VL-4B-Instruct多模态大模型的过程。重点包括:1)环境配置,需注意vLLM 0.11.0、torch和flash-attn版本的兼容性;2)模型部署时需控制上下文长度(max_model_len=4096)和显存占用;3)提供了基于vLLM API和transformers两种调用方式,支持图像和文本的多模态输
-model /opt/models/Qwen3-14B-AWQ \# HuggingFace模型名或本地模型路径。--quantization awq \# 量化方式(若加载 AWQ 模型)--trust-remote-code \# 信任远程代码(Qwen 需要)python client_chat.py --ask "你是谁?--host 0.0.0.0 \# 监听所有 IP。--port
本文介绍了在Windows 11上安装WSL2和配置Linux开发环境的完整步骤。主要内容包括:1)启用WSL和虚拟机平台功能;2)更新WSL到最新版本;3)下载并安装Ubuntu镜像;4)配置WSL网络和DNS设置。同时还提供了在Linux环境下安装Ollama服务的方法,包括下载AI模型LLM。最后介绍了在Windows下运行Claude Code的配置过程,包括安装Git、Node.js,设
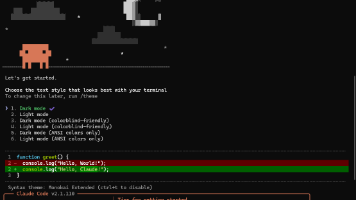
修改后续所有的 model_name: qwen3-8b# qwen3-8b 是settings里面配置的 做了一个模型名映射, 直接填写 qwen3:8b 无法识别。# 添加额外参数确保兼容性 --实际使用中不添加在java的llm调用处有解析异常。model: 'qwen3:8b' # 我用的是这个模型 通过。apikey: 'ollama-api-key'#可以为空。以上配置已测试通过 本机

本地部署index-tts克隆语音 docker镜像
<欢迎使用 >c++实现的用于windwos平台的守护进程.可以监听一组程序,保证不被关闭或者异常杀死.请查看使用说明.下载连接: https://pan.baidu.com/s/1miP2OOSgithub: https://github.com/15608447849/cppCode 实现原理: 1. 通过过 互斥锁(Mutex) 保证程序只...
KAFKA_LISTENERS不写Ip监听0.0.0.0 9092用于 外部kafka客户端/消费端 和kafka服务端通讯 9093用于 kafka内部使用选举及监控等。KAFKA_ADVERTISED_LISTENERS kafka对外暴露的IP和端口 docker内写宿主机IP。KAFKA_AUTO_CREATE_TOPICS_ENABLE 不自动创建topic主题。(一定要加上 红色部分
本地部署index-tts克隆语音 docker镜像
KAFKA_LISTENERS不写Ip监听0.0.0.0 9092用于 外部kafka客户端/消费端 和kafka服务端通讯 9093用于 kafka内部使用选举及监控等。KAFKA_ADVERTISED_LISTENERS kafka对外暴露的IP和端口 docker内写宿主机IP。KAFKA_AUTO_CREATE_TOPICS_ENABLE 不自动创建topic主题。(一定要加上 红色部分
处理: 虚拟环境下找到 \Lib\site-packages\huggingface_hub\constants.py。进入虚拟环境后 pip installcu121-cp310-cp310-win_amd64.whl。│└── v1-5-pruned-emaonly.safetensors# 模型文件。Hugging Face 访问不了可以去魔搭社区。重启UI 就可以选中目标模型。问题 分词器
