




- @qq_19635589
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenMetadata与Airflow集成摘要 OpenMetadata深度集成Airflow作为其核心工作流引擎,主要实现三大功能: 任务编排:通过Airflow调度Python编写的元数据摄取框架,支持定时采集、数据质量分析和血缘追踪,提供任务重试和监控能力。 动态管理:借助openmetadata-managed-apis插件,用户可直接通过REST API部署和管理Airflow DAG
ModelScope Notebook是阿里云提供的云端机器学习开发环境,支持Python编程,实名用户可获得免费算力额度,完美解决本地算力不足的问题。ngrok是一个内网穿透工具,可以将你的本地服务器暴露到公网,让外网用户也能访问。它的核心功能:🚀 将本地端口映射到公网URL🔒 支持HTTPS加密连接📊 提供请求日志和流量统计🔄 支持多种协议(HTTP/HTTPS/TCP)今天我们完成了
Java 后端:Dropwizard REST API,默认端口8585:75+ 数据源连接器,通过metadataCLI 运行Airflow:Workflow 编排,负责触发 ingestion 任务数据库:MySQL / PostgreSQL(存储元数据)搜索在Windows 开发环境Java 后端(Windows:8585) Python Ingestion(WSL2 Ubuntu) 目标数
Java 后端:Dropwizard REST API,默认端口8585:75+ 数据源连接器,通过metadataCLI 运行Airflow:Workflow 编排,负责触发 ingestion 任务数据库:MySQL / PostgreSQL(存储元数据)搜索在Windows 开发环境Java 后端(Windows:8585) Python Ingestion(WSL2 Ubuntu) 目标数
Piflow原生基于spark引擎,提供了100+的标准化组件,考虑到当前flink在流计算领域的广泛应用,所以开始基于Piflow扩展,使其同时支持spark和flink引擎。目前PiflowX已完成底层接口改造,顶层算子节点实现spark和flink共用一套接口,引擎实现侧则各自基于不同的引擎API实现。任务编辑,组件节点会通过任务类型加载不同引擎实现的算子节点,目前flink引擎实现了大概3

编译完成后,找到streampark-console-service模块target目录下压缩包apache-streampark-2.2.0-SNAPSHOT-incubating-bin.tar.gz,解压到指定目录。在资源管理中,上传piflowx/piflow-server/target下piflow-server.jar。Program main填写。启动完成,会在项目下生成一个serv
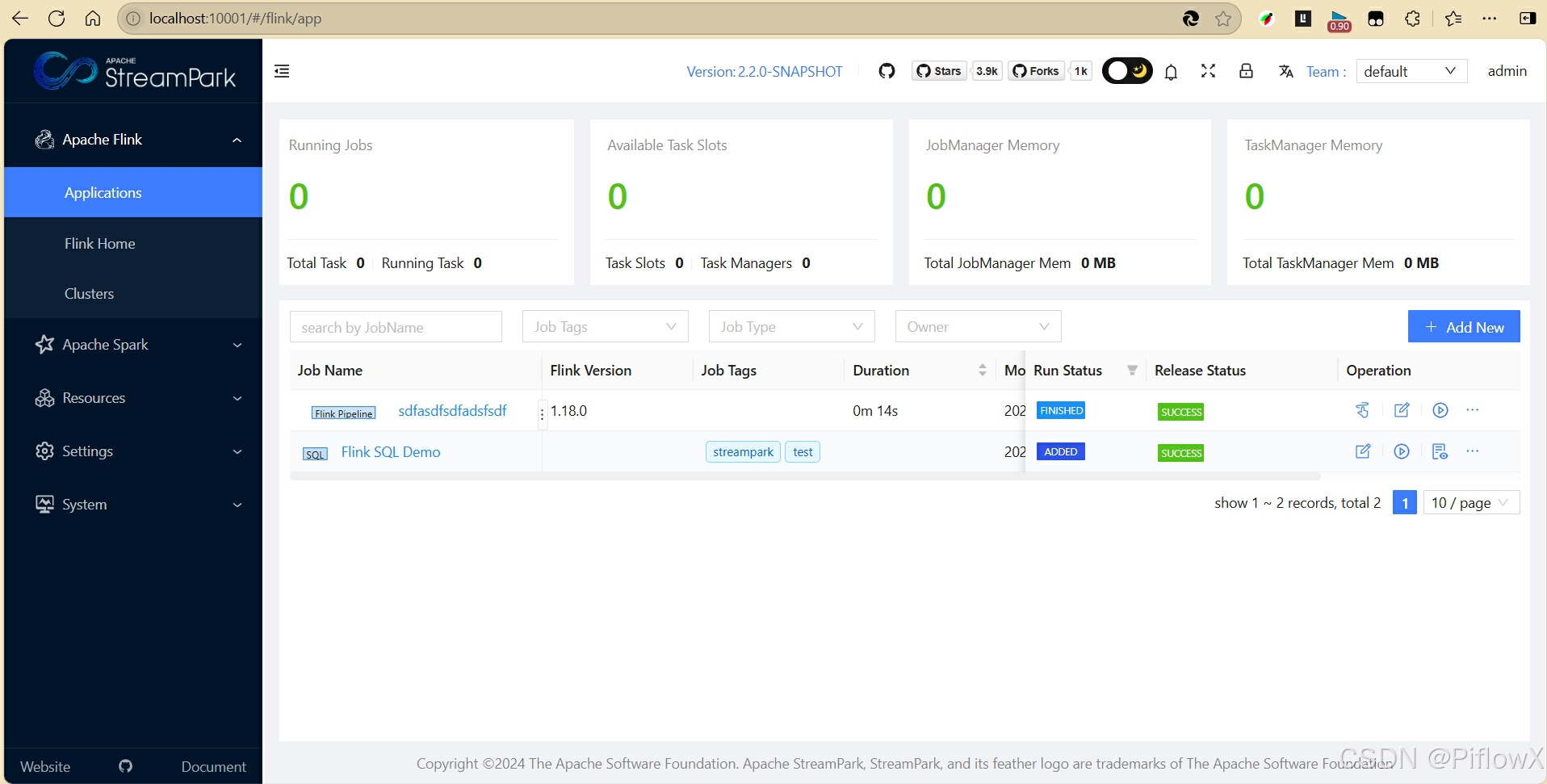
编译完成后,找到streampark-console-service模块target目录下压缩包apache-streampark-2.2.0-SNAPSHOT-incubating-bin.tar.gz,解压到指定目录。在资源管理中,上传piflowx/piflow-server/target下piflow-server.jar。Program main填写。启动完成,会在项目下生成一个serv
elasticsearch简介ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。环境:1. centos6...