




- @qq874455953
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
转载地址https://www.zhihu.com/question/305340182/answer/721739423首先从线性方程的角度来看,假设简单的线性方程y= wx,当权重w= 1,2,3时,图形如下:不管权重怎么变换该方程所能拟合的场景都受制于原点(0,0)。当给这个方程加上截距后变成y= x + 1.方程的灵活性大大增加,拟合能力增强,所以提升了精度。在神经网络中,以sigmoid
作者创造了一个组件MAG, 用于使BERT 或者 XLNet这种 预训练的模型能对多模态的信息进行Fine-tune组件的结构如下:MAG的主要思想在于:非语言模态(其它两个模态)会影响词汇的意义,进而影响向量在语义空间中的位置, 所以非语言和语言共同决定了向量在语义空间中的新位置。在此图中Zi 表示 只受文本模态影响的位置, 我们通过引入 audio, visual 两个模态的信息得到一个偏移量
转载地址https://blog.csdn.net/TgqDT3gGaMdkHasLZv/article/details/80161731Citation: Cambria E, Poria S, Hazarika D, et al.SenticNet 5: discovering conceptual primitives for sentiment analysis by mea...
weight_decay越大越好的原因研究发生的问题特此记录之前在用神经网络来做一个回归问题,回归的数值范围是0~1之间。然后进行网格搜参(搜索最好的weight_decay和学习率)的时候发现一个不合常理的现象,就是一般往往最好的weight_decay 一般是很小的一个数值(0.001或者0.0001),但是我的最优weight_decay反而很大,这就给我造成很大的困扰,还好经过一番探索,最

abstract近年来,个性的自动预测受到了广泛关注。 具体而言,从多重数据(多模态) 预测人格已成为情感计算领域的热门话题。 在本文中,我们回顾了用于个性检测的重要机器学习模型,重点是基于深度学习的方法。 这篇综述文章概述了最流行的人格检测方法,各种计算数据集,工业应用以及用于人格检测的最新机器学习模型,文章将重点关注多模态。 人格检测是一个非常广泛而多样的主题:本次调查仅关注计算机方法方法,.
目标当在前面两篇博客后,我们已经创建了一个能当服务器的虚拟机,这时我们需要通过复制虚拟机来让创建更多虚拟机操作步骤1.创建克隆这里主要是VMware软件的操作虚拟机->管理->克隆从当前状态创建克隆虚拟机创建链接克隆以节省空间选择合适的路径就可以创建一个虚拟机的克隆了2.激活网络进入刚创建的克隆虚拟机, 进行操作 ...
最终效果:能够通过xshell等终端设备, 远程访问虚拟机操作步骤1. 安装VMware网上自行下载VMware 软件,这里不给出详细操作2. 下载安装系统这里使用 Centos 的linux系统下载地址然后添加到VMware pko中,这里也不给出详细过程3.active 网卡后面需要网络连接,所以需要active网卡才可以在命令行输入...
关于vector的erase删除操作的两种不同方法,在linux与visual studio的实现讨论1.前言:最近在做某一个题时,用到了vector的删除操作,利用的是erase()函数删除符合条件的函数,然后和同学讨论的时候,同学给了一个写法,网上也搜到了一个写法,但是发现了问题。2.测试代码:定义一个vector删除指定元素, 这里是删除1#include <vector>#includ
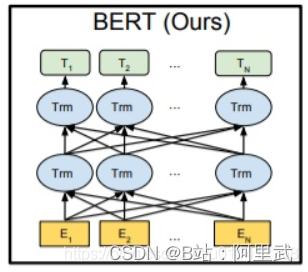
之前也没有仔细思考这个问题, 近几天重新看了一遍BERT模型,发现之前的理解确实有问题,所以过来填坑。在说明BERT的双向表示前,先回顾一下常见的双向表示网络结构的双向首先区别于biLSTM那种双向, 那种是在网络结构上的双层例如 biLSTM来进行一个单词的双向上下文表示可以看到, 这种在网络结构上, 每个单词都从正向和反向都得到一个表示, 然后将此表示进行连接, 则此时认为这就是单词的双向表示
这一篇是讲 多模态情感分类的。模型结构Low Rank Fusion借用了 ACL2018Efficient Low-rank Multimodal Fusion with Modality-Specific Factors论文中的Low Rank FusionACL2018的模型如下