- @qinduohao333
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
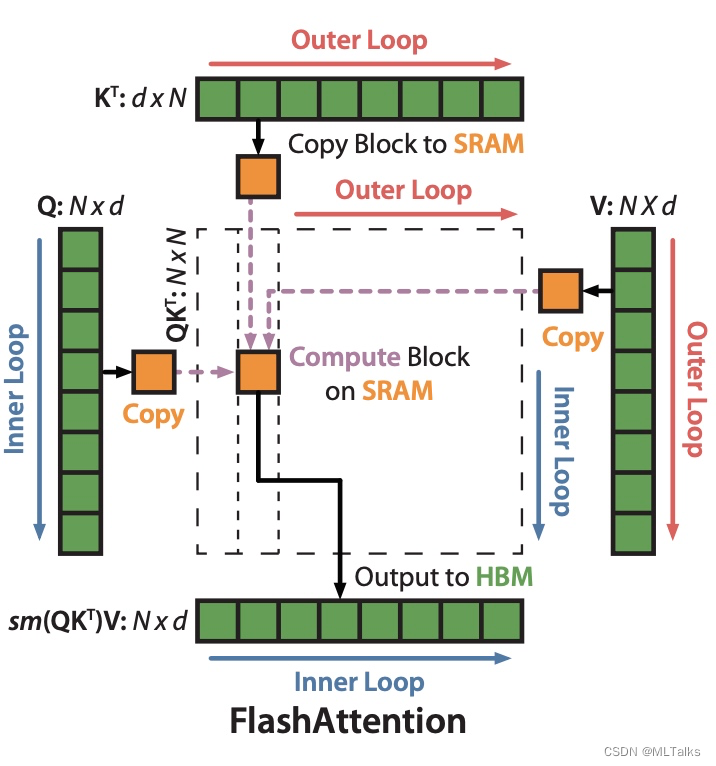
因为Transformer的自注意力机制(self-attention)的计算的时间复杂度和空间复杂度都与序列长度有关,所以在处理长序列的时候会变的更慢,同时内存会增长更多。通常的优化是针对计算复杂度(通过FLOPs数衡量), 优化会权衡模型质量和计算速度。在FlashAttention中考虑到attention算法也是IO敏感的,通过对GPU显存访问的改进来对attention算法的实现进行优化
第一次接触深度学习/机器学习?这些基本概念你必须要掌握!写在前面本文作为入门讲解,适合于首次接触机器学习/深度学习的新人以及从事相关人工智能行业的初级从业人员,对深度学习和机器学习已经有相当了解的朋友请绕行。:)本文简单,仅需要掌握初中数学即可,请放心阅读。基本概念一箩筐什么是样本? 什么是训练?什么是预测?什么是算法?什么是特征?什么是标签?什么是模型文件?什么是模型参数?一下...
Switch Transformers也是google在2022年发表的一篇论文, 该论文简化了MoE的路由算法, 减少了计算量和通信量; 第一次支持bfloat16精度进行训练. 基于T5-Base和T5-Large设计的模型在相同的算力下训练速度提升了7x倍; 同时发布了1.6万亿(1.6 trillion)参数的MoE模型,相比T5-XXL模型训练速度提长了4x倍.

2022年google在`GShard`之后发表另一篇跟MoE相关的paper, 论文名为`GLaM (Generalist Language Model)`, 最大的GLaM模型有1.2 trillion参数, 比GPT-3大7倍, 但成本只有GPT-3的1/3, 同时效果也超过GPT-3.

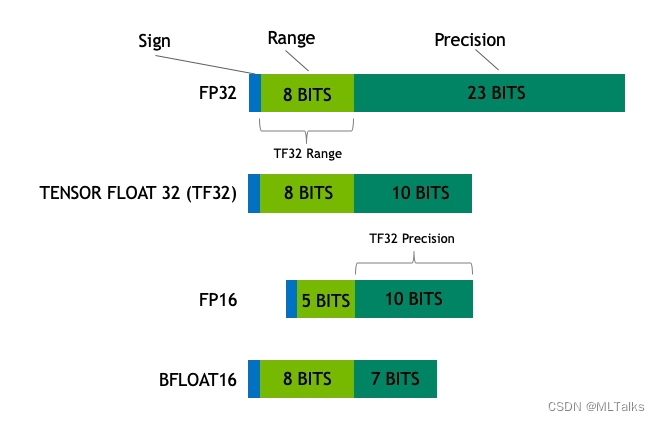
FP16数据格式详解浮点数的格式通常由三部分组成:符号位(Sign bit)、指数部分(Exponent)和尾数部分(Significand/Fraction)。整个浮点数占用的位数取决于不同的浮点数格式。
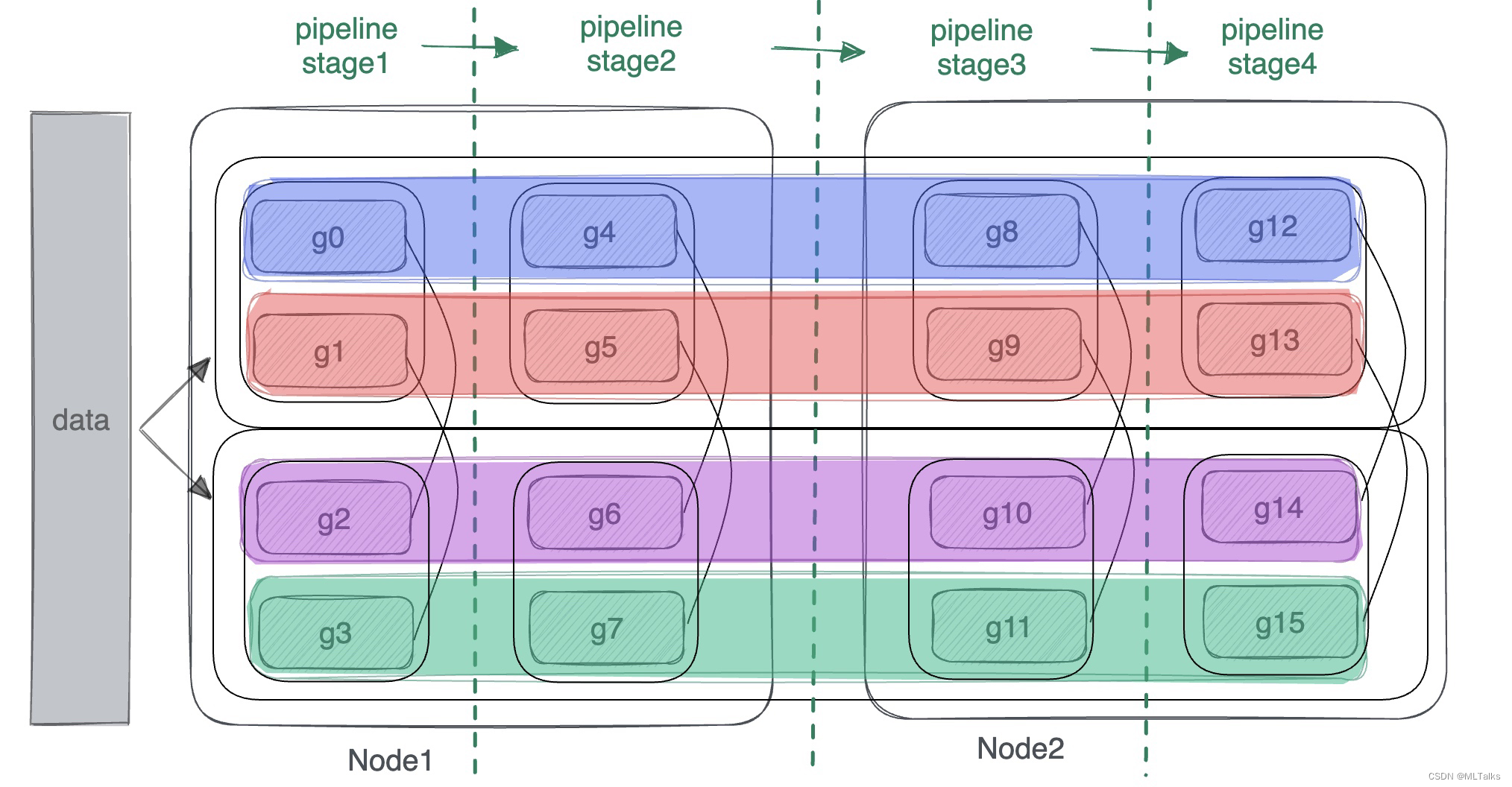
在【Megatron-LM源码系列(二):Tensor模型并行和Sequence模型并行训练】基础上增加了Pipeline模型并行训练的介绍,对于Pipeline模型并行思路可参考【详解MegatronLM流水线模型并行训练(Pipeline Parallel)】。pipeline并行中网络是按层的粒度进行纵向切分,在通信组通信上中在pipeline的不同stage中进行横向通信。
`MegatronLM`的第一篇论文Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism是2020年出的,针对billion级别的模型进行训练,例如具有38亿参数的类GPT-2的transformer模型和具有39亿参数的BERT模型.。
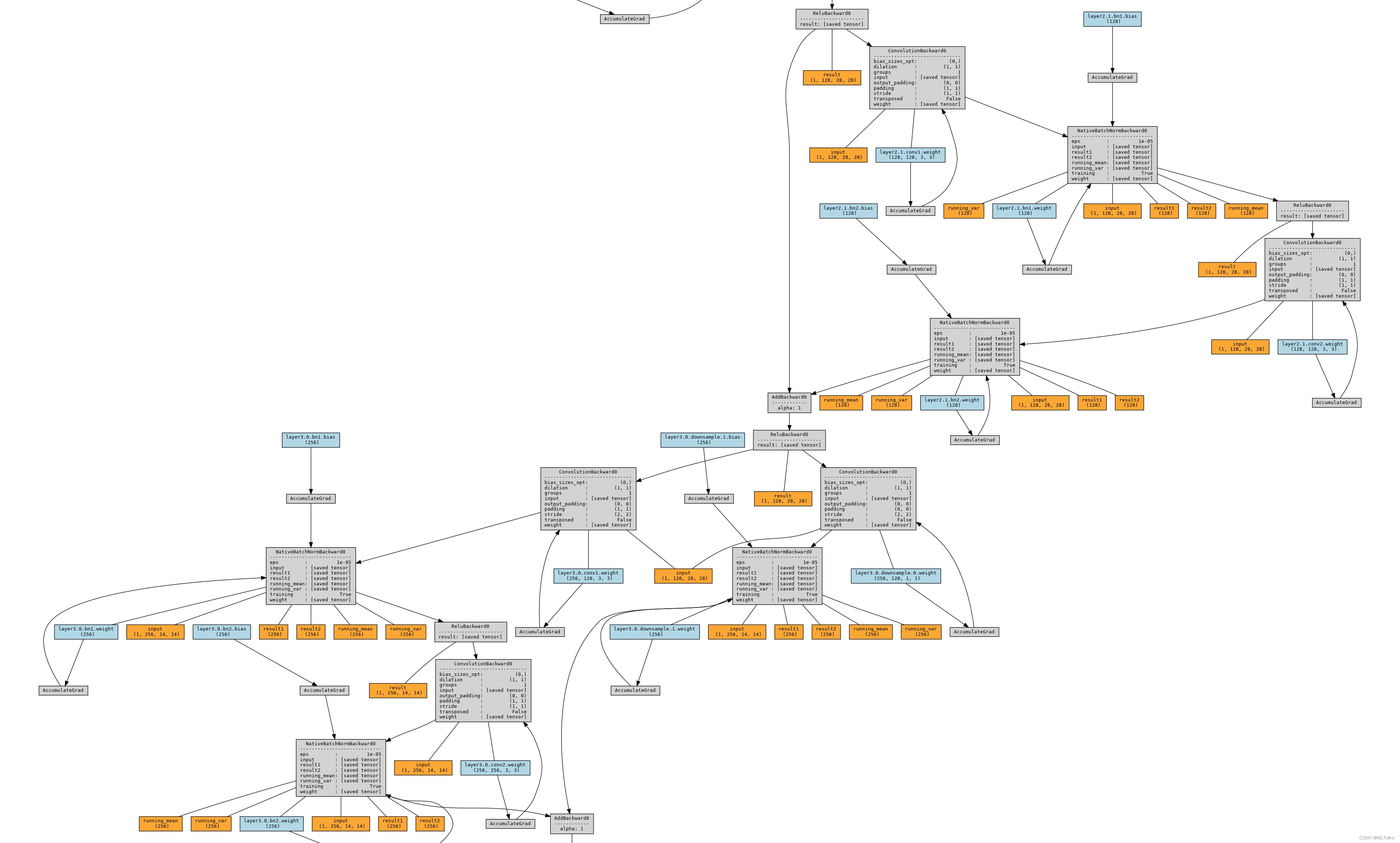
在PyTorch中,有几种不同的工具可以用于网络结构的可视化。下面将以ResNet-18为例,展示如何使用常用的PyTorch画图工具进行网络结构的可视化。
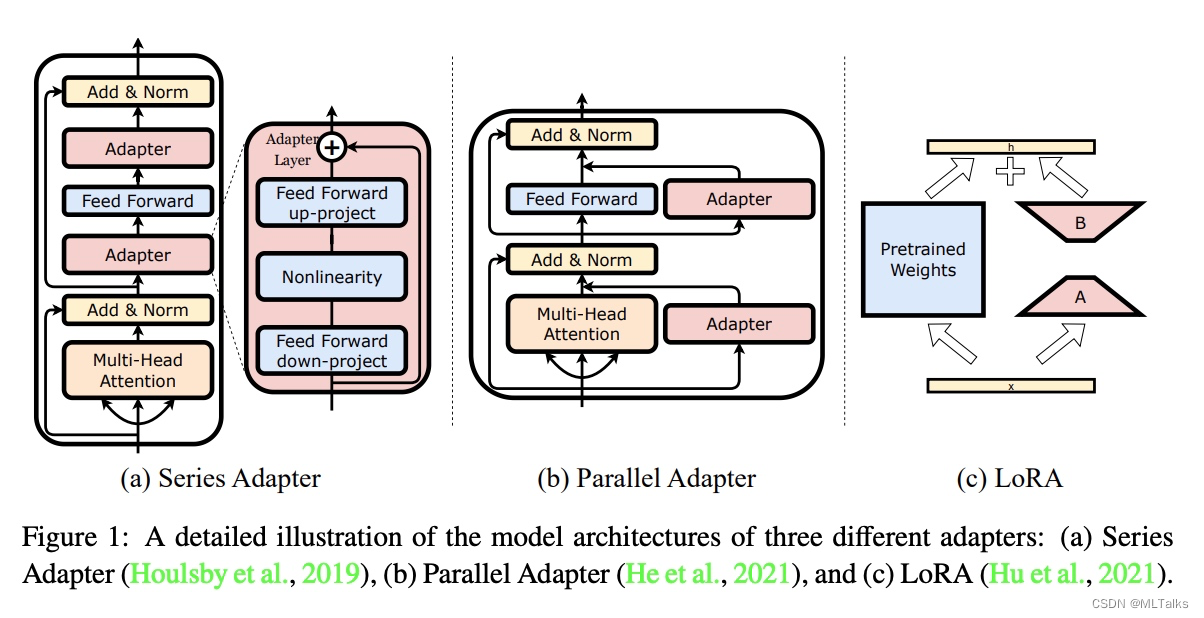
以GPT-3 175B参数量为例,过大的参数量在Finetune的时候代价很大,Adapter适配器方法是进行大模型微调的方法之一。本文详细介绍了大模型微调方法LoRA和代码实现
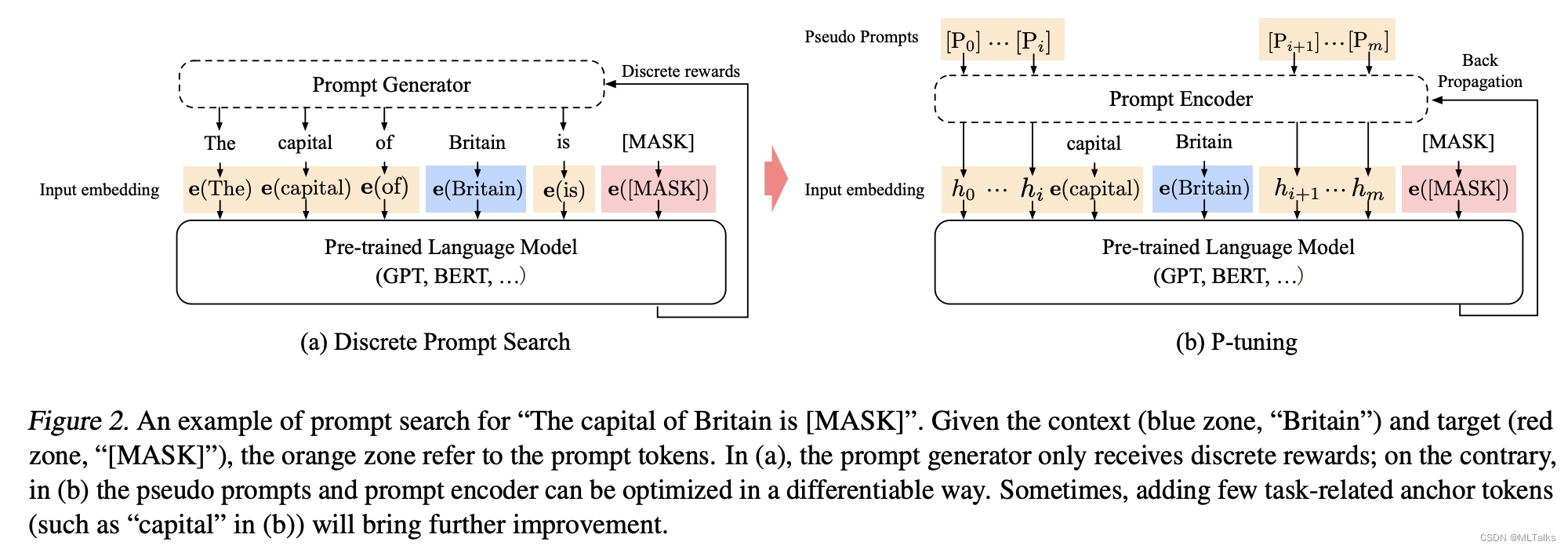
Prompt Tuning是现在大模型微调方法中的一种常用方法,本文通过解读5篇论文来了解Prompt Tuning方法演进的过程。分别是Prefix-Tuning、P-Tuning v1、Parameter-Efficient Prompt Tuning、P-Tuning v2。