




- @panbaoran913
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
方面,随着深度强化学习理论和应用研究不断深入,其在游戏、机器人控制、对话系统、自动驾驶等领域发挥重要作用;另一方面,深度强化学习受到探索-利用困境、奖励稀疏、样本采集困难、稳定性较差等问题的限制,存在很多不足. 面对这些问题,研究者们提出各种各样的解决方法,新的理论进一步推动深度强化学习的发展,在弥补缺陷的同时扩展强化学习的研究领域,延伸出模仿学习、分层强化学习、元学习等新的研究方向. 文中从深度

参考链接:https://blog.csdn.net/liweibin1994/article/details/79093453一、动态规划求Q和V我们的目标是要得到最优策略,使得累积回报函数最大。因此我们的强化学习的优化方法有两种:基于策略的优化(类似于上一篇chap2中的Q*(s,a)的优化)基于累积回报函数的优化(类似于上一篇chap2中V*(s)的优化)1.1 策略评估(迭代法)问题:评估
本文提出了一种在强化学习中实现时间抽象的方法,通过引入"选项"(Options)概念来扩展马尔可夫决策过程(MDP)框架。选项是包含策略、终止条件和启动集的三要素封装,能够表示持续一段时间的行动序列。研究发现,定义在MDP上的选项集合构成半马尔科夫决策过程(SMDP),但最有趣的问题在于底层MDP与SMDP的交互。论文展示了三个关键应用:通过中断选项改进规划效果,开发从执行片段

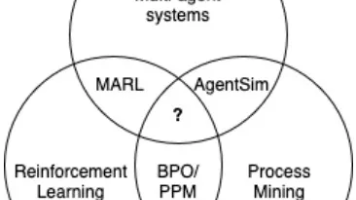
本文提出了一种基于多智能体强化学习(MARL)的处方过程监控方法,重点研究了MAPPO和QMIX算法在业务流程优化(BPO)中的应用。通过构建MASTER模拟平台,将资源建模为自主智能体,支持部分可观测性和事件日志驱动的任务分配。研究探讨了MARL在BPO中的适用性,比较了不同算法在数据集上的性能差异,并提出了一种结合集中训练与分散执行的框架。实验结果表明,该方法能有效优化任务分配策略,提高流程效
参考链接:https://blog.csdn.net/liweibin1994/article/details/79093453一、动态规划求Q和V我们的目标是要得到最优策略,使得累积回报函数最大。因此我们的强化学习的优化方法有两种:基于策略的优化(类似于上一篇chap2中的Q*(s,a)的优化)基于累积回报函数的优化(类似于上一篇chap2中V*(s)的优化)1.1 策略评估(迭代法)问题:评估
本手册是使用 Caltrans 绩效测量系统 (PeMS) 作为支持车道关闭活动的工具的综合指南。 它旨在成为 Caltrans 车道关闭工作人员(包括区域交通经理 (DTM) 和交通管理计划 (TMP) 工程师)进行关闭前设计阶段分析、实时监控车道关闭和评估拥堵情况的资源 以及关闭发生后的安全影响。 虽然本手册确实介绍了基本的 PeMS 报告和导航,但读者可以参考 PeMS 手册简介以更全面地概
DataFrame-数据创建与导入DataFrame的基础用法和了解姓名类型成绩0张三高中891李四初中902特征第一行为字段,即列名,从第二行开始为一行一行的记录每列可以是不同的值类型(数值/字符串/布尔值等)即有行索引也有列索引3获得DataFrame的两种方式3.1 自己创建DateFrame3.1.1通过字典的方式创建DataFrame通过单层字典创建通过嵌套字典创建注意a
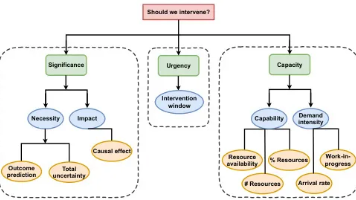
本文提出了一种基于强化学习(RL)的资源受限规范性流程监控(PrPM)方法。该方法通过预测模型、因果模型和生存模型评估干预的必要性、效果及时机,并结合共形预测技术处理不确定性。离线阶段进行数据预处理并训练预测、因果和生存模型;在线阶段利用RL代理实时决策,动态调整干预策略。系统还包含容量监控组件,跟踪资源利用率和工作量,以优化资源分配。实验表明,该方法能有效平衡干预时机与资源限制,显著提升流程效率
本文提出了一种基于多智能体强化学习(MARL)的处方过程监控方法,重点研究了MAPPO和QMIX算法在业务流程优化(BPO)中的应用。通过构建MASTER模拟平台,将资源建模为自主智能体,支持部分可观测性和事件日志驱动的任务分配。研究探讨了MARL在BPO中的适用性,比较了不同算法在数据集上的性能差异,并提出了一种结合集中训练与分散执行的框架。实验结果表明,该方法能有效优化任务分配策略,提高流程效
本文综述了多智能体强化学习(MARL)在无人机控制领域的应用。首先介绍了强化学习的基本概念,包括单智能体强化学习(SARL)和多智能体强化学习(MARL)的区别,重点分析了MARL面临的挑战如信用分配问题、计算复杂度增加等。然后详细阐述了MARL的理论基础马尔可夫博弈,以及三类主要算法:基于价值、基于策略和演员-评论家方法。特别对基于价值的QMIX算法进行了深入解析,包括其集中式训练分散式执行的架
