- @paixiaoxin
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出了一种新的方法,称为可泛化SAM(GenSAM),旨在解决伪装物体检测(COD)中对手动提示的严格要求。传统的伪装物体检测方法依赖于像素级标注数据集,而弱监督COD(WSCOD)方法虽然减少了标注工作量,但仍需稀疏标注,导致准确性下降。GenSAM通过引入跨模态思维链提示(CCTP)和渐进式掩码生成(PMG)机制,利用通用文本提示自动生成和优化视觉提示,从而消除对实例特定手动提示的需求。

本文提出了一种名为TOP-ReID的多光谱目标重识别(ReID)框架,旨在利用来自不同图像光谱的互补信息来提高目标重识别的性能。传统的单光谱ReID方法在复杂视觉环境中表现有限,尤其是在低分辨率、黑暗和眩光等条件下。TOP-ReID通过引入循环令牌置换模块(TPM)和互补重建模块(CRM),有效地解决了不同图像光谱之间的分布差距和缺失光谱问题。TPM通过对不同光谱的特征进行循环排列,促进了空间特征

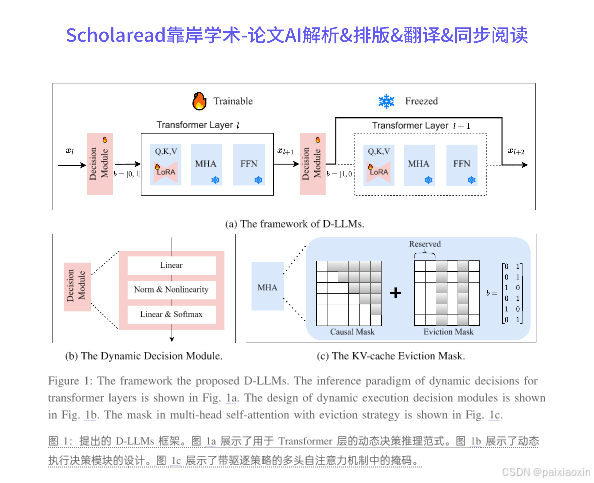
本文提出了一种名为D-LLM的新型动态推理机制,旨在为大型语言模型(LLMs)自适应地分配计算资源。当前,LLMs对每个词元的处理是等同的,但作者认为并非所有词语都同等重要,某些词语在简单问题中并不需要过多的计算资源。D-LLM通过为每个Transformer层设计动态决策模块,决定是否执行或跳过该层,从而提高推理速度。此外,本文还提出了一种有效的驱逐策略,以解决跳过层时KV缓存缺失的问题。
本文提出了一种名为Differentially-Private Offsite Prompt Tuning(DP-OPT)的新方法,旨在解决大型语言模型(LLM)提示微调中的数据隐私问题。DP-OPT通过在客户端调整离散提示,并将其应用于云端模型,确保了数据的保密性和隐私性。该方法利用差分隐私技术,生成可在不同模型间迁移的提示,同时保护了提示不泄露私人信息。实验表明,DP-OPT在多种语言任务上表

本文提出了GMMFormer,一种基于高斯混合模型的Transformer,旨在高效地进行部分相关视频检索(PRVR)。PRVR任务旨在从未剪辑视频中检索与给定文本查询部分相关的片段。现有的PRVR方法通常采用显式片段建模,导致信息冗余和存储开销大。GMMFormer通过隐式建模片段表示,利用高斯混合模型约束,使每帧关注其相邻帧,从而生成包含多尺度片段信息的紧凑嵌入。此外,本文还提出了一种查询多样

本文研究了音频-视觉问答(AVQA)任务,旨在回答来自未剪辑音频视频的问题。为了生成准确的答案,AVQA模型需要找到与给定问题相关的最具信息量的音频-视觉线索。本文提出了一种面向对象的自适应正例学习策略,明确考虑视频帧中的细粒度视觉对象,并探索对象、音频和问题之间的多模态关系。通过设计问题条件线索发现模块和模态条件线索收集模块,模型能够集中注意力于与问题相关的关键词,并突出显示相关的音频片段或视觉

本文提出了一种名为SelfPromer的自提示去雾Transformer,旨在通过深度一致性来改善图像去雾效果。研究表明,含雾图像的深度估计与其清晰对应图像之间存在显著差异,因此强制去雾图像与清晰图像之间的深度一致性至关重要。SelfPromer通过生成基于深度差异的提示,指导去雾模型进行更好的恢复。该方法结合了提示嵌入模块和提示注意力模块,以更好地感知和去除雾霾残留。通过在VQGAN基础上构建的

本文提出了一种新的方法——链式偏好优化(CPO),旨在提高大型语言模型(LLMs)在复杂问题解决中的推理能力。尽管链式思维(CoT)解码能够生成明确的逻辑推理路径,但研究表明这些路径并不总是最佳的。树形思维(ToT)方法通过树搜索探索推理空间,发现CoT可能忽略的更优路径,但其推理复杂度显著增加。CPO通过利用ToT构建的搜索树对LLMs进行微调,使得CoT能够在不增加推理负担的情况下实现类似或更

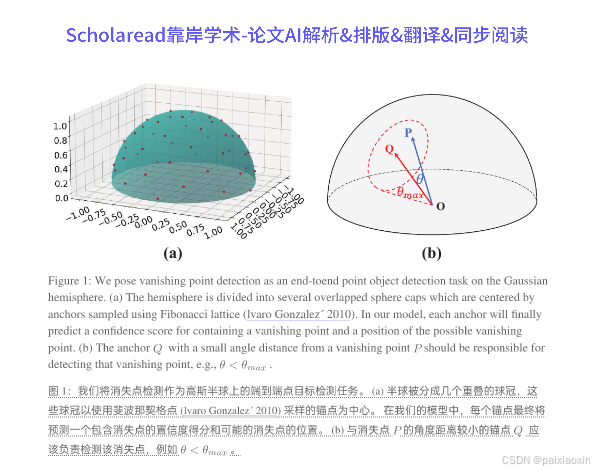
本文提出了一种新颖的基于Transformer的端到端实时消失点检测方法,称为消失点Transformer(VPTR)。该方法通过将消失点检测视为在高斯半球上的点目标检测任务,能够直接从给定图像中回归消失点的位置。VPTR架构结合了CNN主干网络和可变形Transformer解码器,能够高效地提取多级图像特征。该方法不依赖于直线检测或曼哈顿世界假设,使其在自然和结构化场景中均表现出色。
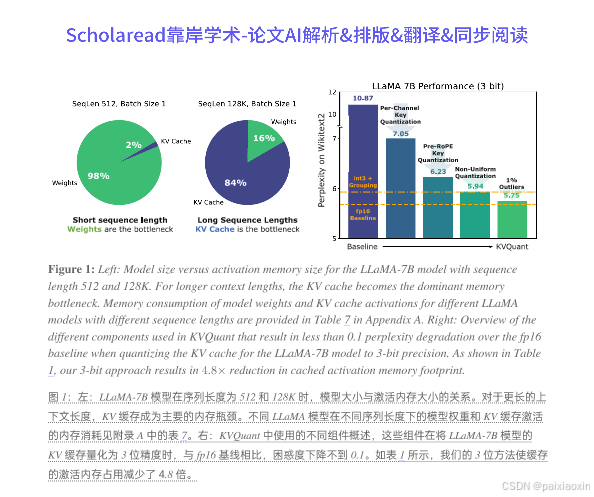
本文提出了KVQuant,一个针对大型语言模型(LLMs)推理的低精度KV缓存量化方法,旨在支持长达1000万上下文长度的推理。随着LLMs在需要大上下文窗口的应用中的广泛使用,KV缓存激活成为推理过程中内存消耗的主要来源。现有的量化方法在低于4位精度时无法准确表示激活。KVQuant通过四种新方法来解决这一问题:逐通道键量化、预RoPE键量化、非均匀KV缓存量化和逐向量稠密与稀疏量化。