




- @myboyliu2007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1 安装R语言R语言是主要用于统计分析、绘图的语言和操作环境。官方网站:http://www.r-project.org/Windows下面有直接的安装包,直接下载安装很方便,但是对于刚出的CentOS6.0上不能直接通过yum 安装R,需要自己编译。下载页面:http://ftp.ctex.org/mirrors/CRAN/1.1更新源到fedoraproject
我们致力于在视频数据上开展生成模型的大规模训练。具体来说,我们针对不同时长、分辨率和宽高比的视频及图像,联合训练了基于文本条件的扩散模型。我们采用了一种 Transformer 架构,这种架构能够处理视频和图像潜在编码的时空片段。我们的最大型号模型,Sora,能生成高质量的一分钟视频。我们的研究显示,扩展视频生成模型的规模是向着创建能够模拟物理世界的通用工具迈出的有前途的一步。本技术报告主要介绍了

NPU推理与微调最佳实践在 Notebook 打开NPU推理与微调最佳实践在 Notebook 打开。

有关插件的一般说明,请参见配置 → 插件。在带宽受限的情况下,或者 Neo4j 经常停止和启动的情况下,可能希望只下载插件一次并重复使用,而不是每次都下载插件。Neo4j Docker 映像包括一个启动脚本,可以在运行时自动下载和配置特定的 Neo4j 插件。此功能旨在简化在开发环境中使用 Neo4j 插件的过程,但不建议在生产环境中使用。要在生产中使用 Neo4j Docker 容器中的插件,请

在 chest X-ray 数据集上做肺分割介绍在此任务中,您将开发一个系统,可以在胸部X光片中自动检测肺部的边界框。对于这项任务,我们将使用一个名为[Yolo]的网络(https://arxiv.org/pdf/1506.02640.pdf) 。有关YOLO(以及最新的YOLOv2 / YOLO9000)方法的详细信息,请参阅以下文章:** YOLO:统一的实时物体检测** [http...
为了结合这些对比方法的优势,我们提出了一种图形 RAG 方法,用于回答关于私人文本语料库的问题,该方法随着用户问题的普遍性和要索引的源文本数量而扩展。对于在 100 万令牌范围内的数据集上的一类全局意义问题,我们展示了图形 RAG 相对于天真的 RAG 基线在生成答案的全面性和多样性方面带来了显著改进。llm 模型期望像 llama3、mistral、phi3 等语言模型,嵌入模型部分期望像 mx

互联网上有大量关于如何构建RAG管道的教程,问题在于,大多数都依赖于在线服务和云工具,特别是在生成部分,许多教程都主张使用OpenAI LLM API,不幸的是,这些API并不总是免费的,而且在处理敏感数据时可能不被认为是可信的。现在我们已经成功地将我们的数据(研究论文)加载到我们的向量存储(Qdrant)中,我们可以开始查询它以获取相关数据,以供我们的LLM使用。Llamaindex支持各种数据

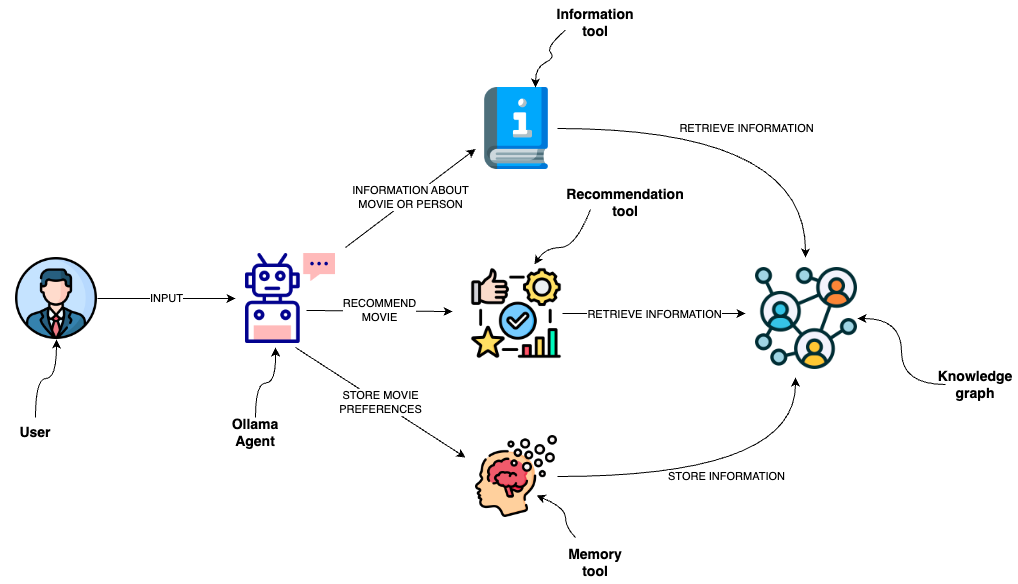
有趣的是,在实施自定义函数之后,我发现了一个现有的LangChain函数,它将自定义的Pydantic工具输入定义转换为Mixtral可以识别的JSON对象。正如提到的,大多数模型没有经过训练来产生行动输入或文本,如果不需要行动,我们必须使用当前可用的内容。它们共同使LLM能够提供更准确的推荐,随着时间的推移了解用户的偏好,并获得更广泛的最新信息,从而实现更具互动性和适应性的用户体验。正如提到的那
许多人谈论思维的重要性,认为这是强化学习在LLMs领域带来的主要促进因素之一,许多论文也表明,思维链可以提高模型的性能,因此认为思维可以改善性能是非常合理的。RL 的另一个有趣特性是我们可以优化不同的目标并手动控制它们的影响,例如,如果我们发现我们的模型在关系提取上很困难,我们可以为正确提取的关系生成的示例分配更高的奖励,与其他特征相比。在开始强化学习之前,考虑到我们使用的是小模型,需要额外的监督

在我的 CPU 上,使用 ONNX 转换可以获得适度的加速。对于编码器,只有批次维度是动态的,因为 whisper 使用固定的 30 秒音频窗口。对于解码器,批次和序列维度,即生成的标记数量,都是动态的。我使用了一个小的 Rust 程序从我的麦克风捕获了 30 秒的样本,并将其转换为梅尔频率倒谱。在接下来的内容中,我将专注于最简单的解码方法,即不带时间戳预测的贪婪解码,并忽略键值缓存。我们用一个固