




- @maray
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一些分布式数据库在这个方面就很吃亏,多副本,为了追求高可靠,就自然要把副本放到多个 AZ 中,这样一来,计算流量就很容易在多个 AZ 之间来回蹿,费用蹭蹭涨。所以啊,云原生的数据库,还是 Snowflake 玩得溜,卡了一个非常好的位,把这些乱七八糟的需求全部绕过了,一个 AZ 管够。那么,如果你在设计产品的时候,就需要时时刻刻把网络这件事情放在心上,最好,每一次查询涉及到的机器都不要跨 AZ。甚
摘要:Neon注册流程简单快捷,支持Google登录并选择AWS/Azure云平台。用户下载客户端后完成授权,即可获取连接串对接AI工具,实现代码直连Neon数据库。整个过程仅需20分钟,最新版本还支持PostgreSQL作为后端,大幅提升开发效率。系统初始化后可直接查看所有数据,为开发者提供极大便利。

本文背景:由于ReviewBoard非常水,diff稍微大一点就会提交失败。那么如何做review呢?不妨利用github/gitlab自带的在线Diff展示功能做。操作过程...
习题(推广的LVQ). 设竞争网络的底层为输入源节点,竞争层的神经元y和底层源节点j的连接权值为wyj。对于C类分类问题, 每个竞争神经元属于类别c的概率为P(yÎc)=exp(acy)/(åcexp(acy)), c=1,2,…C.那么输入向量x,它的属于类别c的概率为P(xÎc)= åy P(yÎc)P(y|x), c=1,2,…C.其中使用最简单的假设P
小智AI是一款由硬件、开源固件和服务端组成的聊天玩具,其台湾腔陪聊功能广受欢迎。最初闭源的服务端被团队复刻并开源,用户无需订阅即可永久使用。该系统整合了国内多家云服务商的免费AI方案,包括智谱的LLM和视觉模块。开发者可通过修改开源固件扩展硬件功能,或通过MCP扩展后端能力。小智的核心交互依赖于液晶显示和语音输入/输出模块,而后端服务则提供了丰富的扩展可能性。
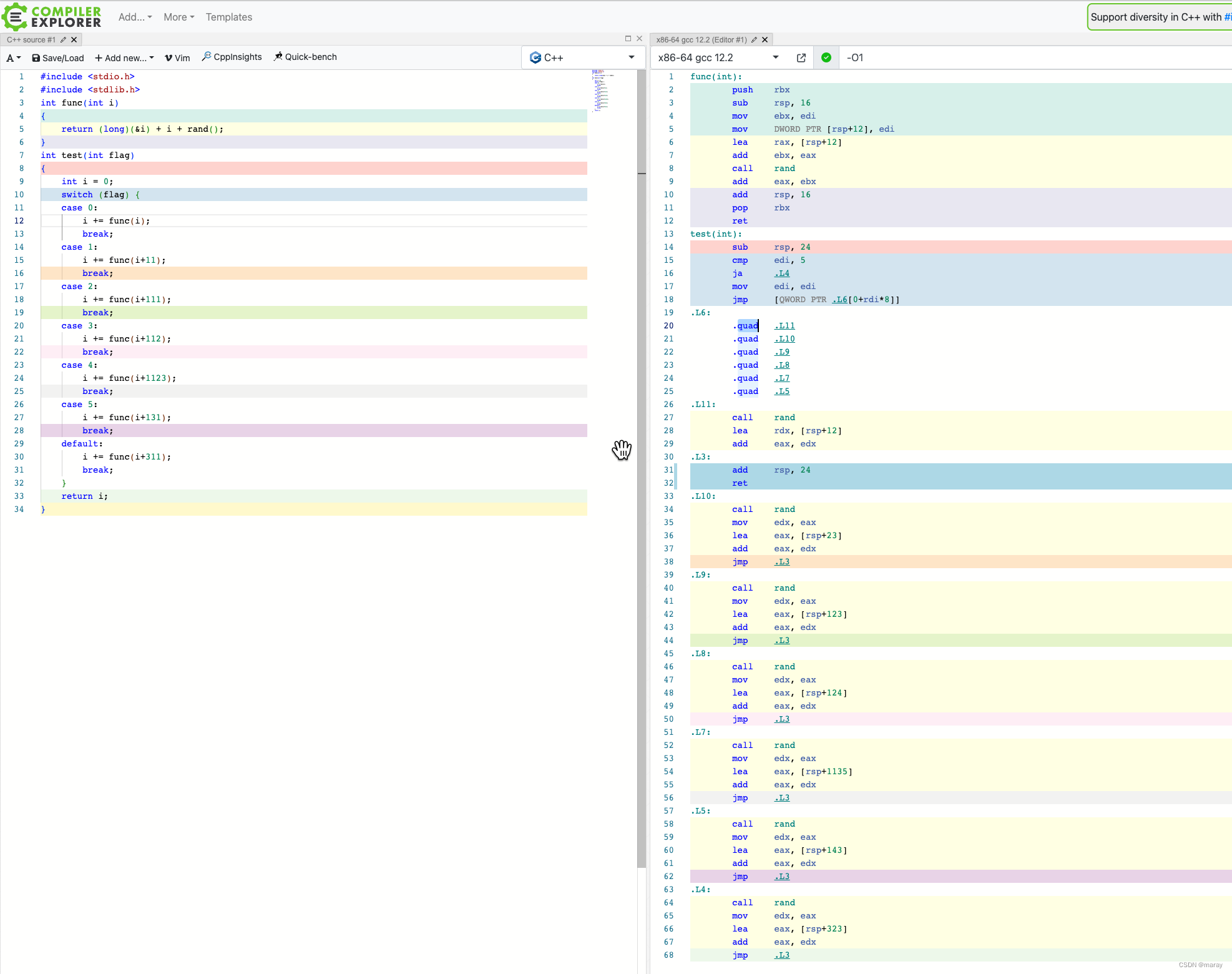
当 switch 的取值 “比较连续” 的情况下,编译器会使用 jump table 技术来优化 switch 的执行。当连续性很差的时候,优化效果不佳。
RDTSC 是 x86 中最为轻量级的计时方案,虽然它不甚精确坑很多,但特定场景下依然好用。海光的 lscpu flags 中支持 RDTSC,本文通过一个简单 benchmark 来看海光的 RDTSC 实现效率(还不错)。
摘要:大模型本质是无状态的,其连续会话能力由外部Agent维护上下文实现。Agent负责编排流程、调用工具和管理交互状态,而大模型仅返回决策结果(文本或工具调用指令)。上下文工程是核心挑战,涉及短期/长期记忆管理、向量检索等技术,以解决对话爆炸问题。数据库领域的AI需求(如embedding)主要服务于高效上下文检索。
应该是提示词还不够详细,生成的内容还需要人工微调一下,但是大体结构是非常好的,只需要稍微花费一点力气就可以调整好。最终,通过稍微的调整,输入了如下代码,效果非常棒。使用 GPT + Manim 生成动画的体验非常好。
你将 Query 传给 Chroma 后,Chroma 内部先用 DuckDB 的 SQL 在磁盘上按 metadata(比如 source=“wiki” 且 date>2024-01-01)筛出候选 id 列表,然后只把这些候选的 embedding 读入内存并计算相似度,减少计算量。可以看到,Chroma 的核心贡献在于向量搜索,至于存储,完全委托给了 duckdb 等嵌入式存储,他们各自发挥