




- @m0_65648831
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ALBEF是一种先进的多模态学习模型,通过图像-文本对比学习实现模态对齐。其核心创新包括:1) 采用不对称编码结构,图像编码器(ViT)比文本编码器(BERT)更深;2) 引入动量模型增强特征对比学习;3) 设计多模态融合模块,通过跨模态注意力机制实现深度交互;4) 提出动量蒸馏技术,利用KL散度减少噪声数据影响。该模型通过图像-文本对比(ITC)、匹配(ITM)和掩码语言建模(MLM)三个任务联
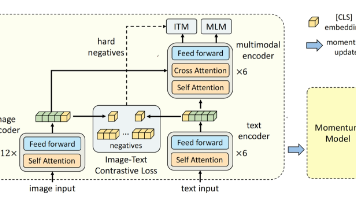
ALBEF是一种先进的多模态学习模型,通过图像-文本对比学习实现模态对齐。其核心创新包括:1) 采用不对称编码结构,图像编码器(ViT)比文本编码器(BERT)更深;2) 引入动量模型增强特征对比学习;3) 设计多模态融合模块,通过跨模态注意力机制实现深度交互;4) 提出动量蒸馏技术,利用KL散度减少噪声数据影响。该模型通过图像-文本对比(ITC)、匹配(ITM)和掩码语言建模(MLM)三个任务联
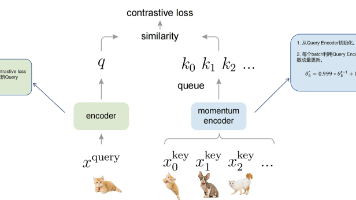
本文探讨了CLIP和MoCo两种突破性模型。CLIP通过图文配对训练实现了无需标注数据的多模态学习,利用prompt技术摆脱了传统分类模型的固定类别限制,开创性地将文本与图像特征映射到共享向量空间。MoCo作为对比学习算法,通过动量编码器和负样本队列解决了无监督学习中样本一致性问题,采用指数移动平均更新策略稳定训练过程。两者共同特点是:1)减少人工标注依赖;2)通过自监督学习提取高质量特征表示;3
本文摘要:文章系统介绍了AI领域的多项关键技术。数据蒸馏部分阐述了三种核心方法(性能匹配、参数匹配、分布匹配),其中参数匹配效果最佳。Scaling Law部分解析了预训练、后训练和推理三个阶段的资源优化法则。RAG准确率提升提出了三种改进方法:智能分词、语义校验和混合检索。大模型训练流程详细说明了数据清洗、预训练、指令微调和偏好对齐四个关键步骤。显存估算部分则从推理和训练两个维度,以7B模型为例
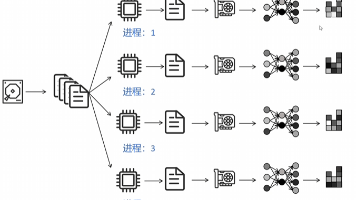
本文系统介绍了深度学习模型分布式训练的技术演进。首先分析了数据并行(DP)模式,指出其单进程多线程的局限性导致GPU0通信压力过大。然后详细讲解了DDP框架采用的ring all-reduce通信机制,通过环形连接实现负载均衡,使每个GPU的通信量恒定为2φ。进一步介绍了DeepSpeed的ZeRO优化方案:ZeRO-1通过划分优化器状态将显存占用降低至31.4GB;ZeRO-2增加梯度划分,显存
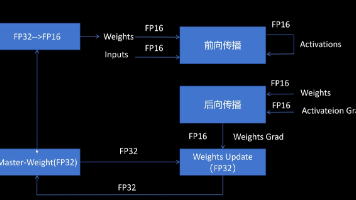
混合精度训练通过结合FP16和FP32数据格式,在保持模型精度的同时显著提升训练速度并减少显存占用。FP16计算速度更快且显存占用减半,但存在数值溢出和大数吃小数问题。混合精度采用主权重(FP32)保存参数,在FP16下进行前向和反向传播,通过梯度缩放和关键操作(如损失计算)保持FP32精度来解决这些问题。该技术已成为大模型训练的标准配置,在PyTorch等框架中已实现自动混合精度支持。
本文介绍了flow matching的基本原理和实现方法。该方法通过神经网络学习一个向量场,该网络输入时间和位置信息,输出速度向量用于调整多维数据。关键问题是如何获取训练标签(速度向量),解决方案是构建一个概率流模型:初始为标准正态分布,随时间逐渐汇聚到目标点Z。通过定义条件概率路径和边缘概率路径,推导出条件向量场的计算公式。训练时,从标准正态分布采样噪声ε,结合目标数据Z计算位置和速度向量。虽然
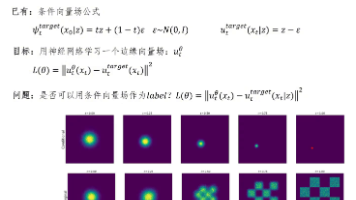
Flow Matching是一种新兴的生成模型方法,通过直接学习概率流将简单分布转换为复杂数据分布。相比传统扩散模型,它具有训练稳定、采样快速等优势。该方法利用向量场指导概率密度的流动,从初始正态分布逐步变形为目标数据分布。关键概念包括轨迹(记录点随时间的位置变化)、向量场(定义运动规则的速度场)和流(轨迹集合)。神经网络通过学习最优向量场,将采样点从初始分布引导至目标分布,实现高效生成。这种技术

GPTQ是一种经典的后训练量化算法,专为大规模预训练模型设计。它属于权重量化方法(weight-only),采用均匀量化方式,支持对称和非对称量化。GPTQ的创新点在于:1)通过统一量化顺序避免重复计算Hessian矩阵;2)采用分组量化策略减少显存带宽压力;3)使用Cholesky分解提高数值稳定性。相比OBQ算法,GPTQ显著提升了量化效率,能在不训练模型的情况下实现W3A16/W4A16的低
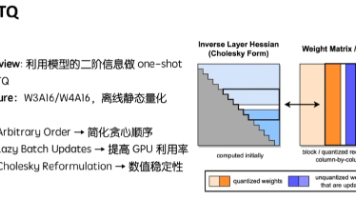
GPTQ是一种经典的后训练量化算法,专为大规模预训练模型设计。它属于权重量化方法(weight-only),采用均匀量化方式,支持对称和非对称量化。GPTQ的创新点在于:1)通过统一量化顺序避免重复计算Hessian矩阵;2)采用分组量化策略减少显存带宽压力;3)使用Cholesky分解提高数值稳定性。相比OBQ算法,GPTQ显著提升了量化效率,能在不训练模型的情况下实现W3A16/W4A16的低