
写文章




- @m0_65532100
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
寻找值得学习的强化学习自定义
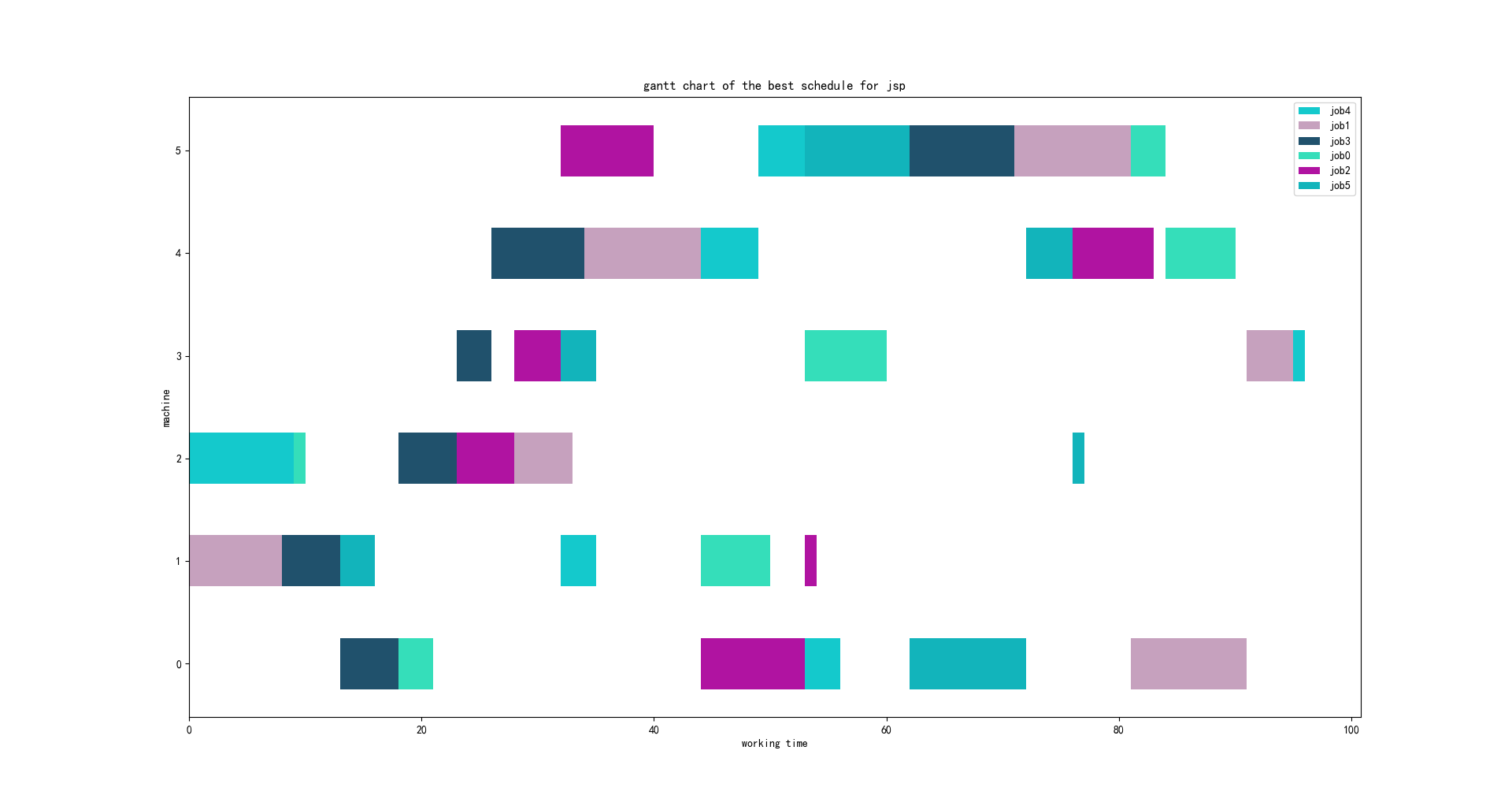
文章目录前言一、隐性扰动人工调整数据?二、车间调度问题的转化2.1.状态空间2.2 动作空间2.3 奖惩函数2.4环境三、深度强化学习算法3.1动作探索策略3.2激活函数的选择3.3 DDPG 算法总结前言标题: 基于深度强化学习的离散型制造企业车间动态调度研究作者:蒋静静文献摘要为了适应变化万千、竞争激烈的市场环境,制造企业向多类型、小规模的离散制造模式转变,导致车间生产过程变得复杂动态,发生突
探索数据——数据可视化
位置度量:均值和中位数对于连续数据,最广泛使用的是均值和中位数,他们是值集位置的度量。为了克服传统均值定义的问题,又是使用截断均值的概念。指定0和100之间的百分位数p,丢弃高端和低端(p/2)%的数据,然后用常规方法计算均值,所得的结果即是截断均值,而标准均值是对应于p=0%的截断均值。散布度量:极差和方差绝对平均偏差(AAD)、中位数绝对偏差(MAD)、四分位数极差(IQR)对于多元数据,每个


到底了